

撰文 | 程书书
编辑 | 李信马
题图 | 百 度
前几天,百度世界大会上,文心大模型4.0发布。而李彦宏宣称,新版本的文心大模型“综合水平与 GPT-4 相比已经毫不逊色”,更是一石激起千层浪。
自此之后,在各家的评测中,文心大模型4.0已经与GPT-4的巅峰对决了N个回合,可以说难解难分。不过,GPT-4虽然是目前世界公认的一流水平,但收费价格不低,对国内用户来说使用也不方便,文心一言却已经面向全社会免费开放。
走路要一步一个脚印,今天DoNews就不整它俩的比拼了,而是测一测文心大模型4.0与目前仍免费的GPT-3.5的差别,看一看现在的文心大模型,是否明显优于后者,如果是的话,那对绝大多数用户来说,选哪个就清楚了。
先说测评维度,这一次的大模型评测,按照业界普遍使用的语言理解、推理、生成、记忆这四个维度。俗话说因地制宜,DoNews安排的题目中,还包括今年国家公务员考试《行测》的真题,真实展现大模型在中文领域的实际水平。
一、理解能力
第一题,据说在中文考试中绕晕外国人的语言理解题目——说曹操到曹操就到了。
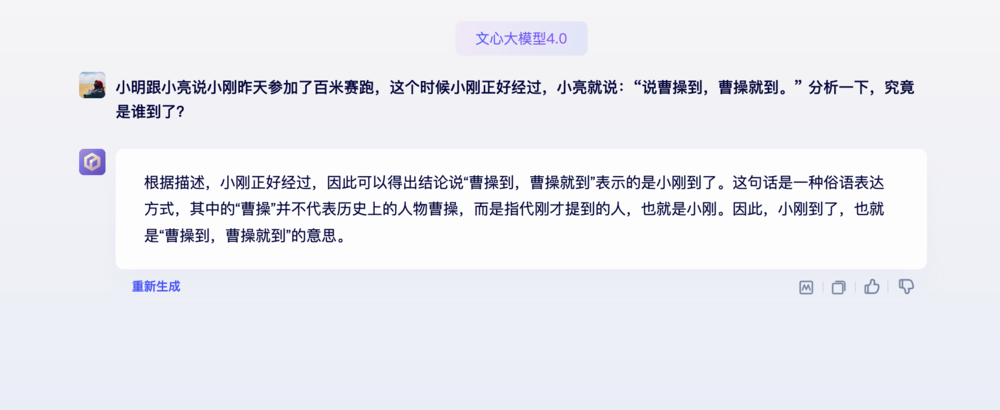
小明跟小亮说小刚昨天参加了百米赛跑,这个时候小刚正好经过,小亮就说:“说曹操到,曹操就到。” 分析一下,究竟是谁到了?
文心大模型4.0的回答如下:
GPT-3.5的回答如下:
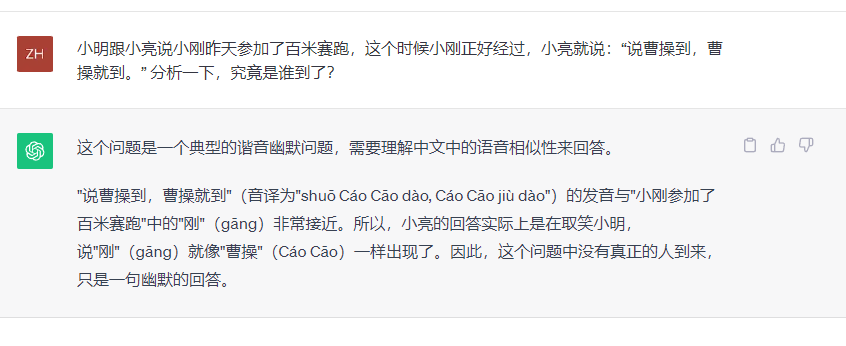
可以看到,文心大模型4.0对于中文谚语理解非常到位,而再看GPT-3.5的回答,只能说一塌糊涂。这一题,文心大模型4.0明显胜出。
刚刚的问题可能有点太欺负外国大模型了,紧接着,DoNews又从今年的国家公务员考试《行测》中扒来一道语言理解与表达试题。
每个企业都有自己的核心价值观,它是企业一切理念、制度和技术的价值基础。企业在重视财务、营销、技术的同时,更应重视员工。员工是企业的主人,是企业的根本,只有建立起以“重视员工”为核心价值观的企业文化,企业才能凝聚员工、创造个性,为自身的发展提供目标、方向和定力。 这段文字意在说明什么?(国家公务员考试《行测》语言理解与表达试题)
文心大模型4.0的回答如下:

GPT-3.5的回答如下:

这一题的结果,应该说是双方势均力敌,文心大模型4.0言简意赅说出重点,GPT-3.5则条理清楚分析出结论。
二、逻辑推理能力
在这一维度,DoNews同样在《行测》找来两道真题,第一道是数学推断计算题。
甲、乙等16人参加乒乓球淘汰赛。每轮对所有未被淘汰选手进行抽签分组两两比赛,胜者进入下一轮。已知除了甲以外,其余任意两人比赛时双方胜率均为50%。甲对乙的胜率为0%,对其他14人的胜率均为100%。则甲夺冠的概率是多少?(国家公务员考试《行测》数量关系试题)
文心大模型4.0的回答如下:

GPT-3.5的回答如下:

不愧是国考题,文心大模型4.0和GPT-3.5都被整懵了,两个答案全部错误。正确的答案是11/15,文心大模型明显是没理解题目的意思,想的过于复杂。GPT-3.5给出来的答案则让人哭笑不得,思路直接就是错的,又想的太过于简单了,很难说哪个更强一点。
第2题就更加高端了,是看图分析规律推理出答案,不过由于GPT-3.5不能查看图片,这一题就只有文心大模型来作答了。

让DoNews没有想到的是,文心大模型4.0不仅可以识别图片问题,还能准确的根据规律得出正确结果,可以说是碾压性胜利。
三、生成能力
在这个维度,DoNews设置了根据描述生成文案、图画以及视频三个测试题。第一题,请根据“吵架”生成一段文案,文心大模型4.0的回答如下:

GPT-3.5的回答如下:
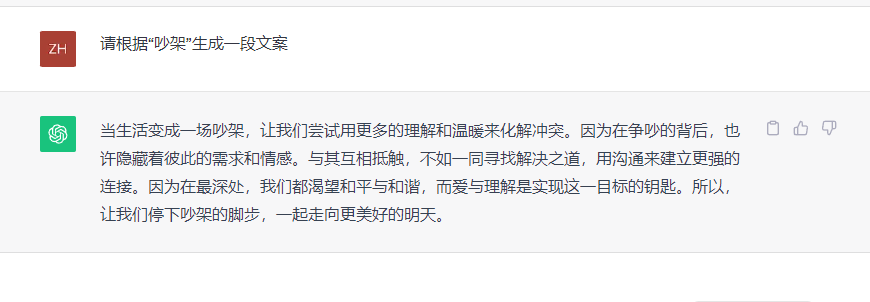
两者算是打了个平手,都是对于“吵架”这一负情绪词进行正向引导。接下来的两题,由于GPT-3.5无法生成图片和视频,可以说文心大模型不战而胜了,来看下结果吧。
请根据“为有暗香来”生成一幅画,文心大模型4.0的回答如下:
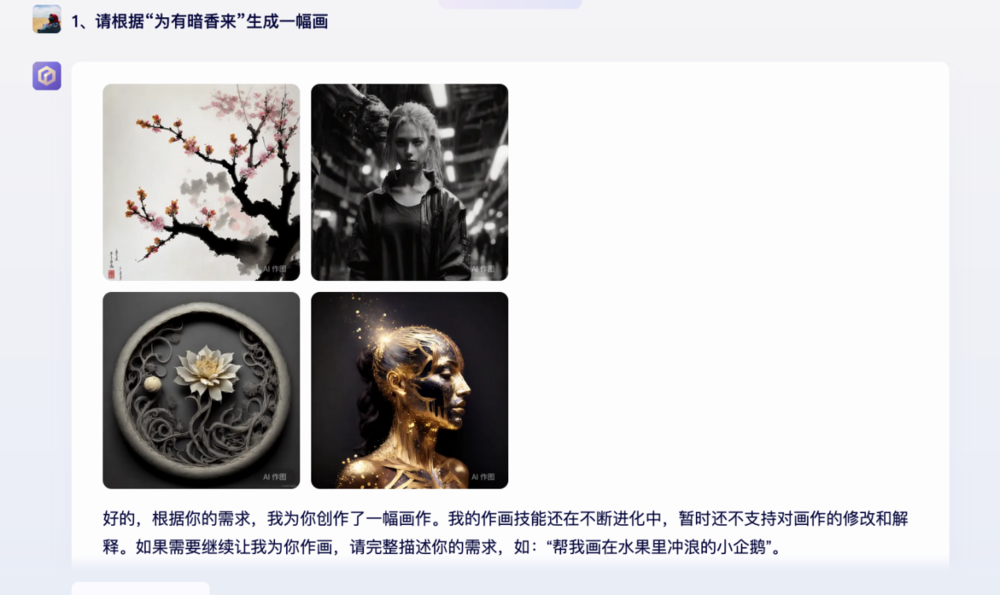
文心大模型4.0直接根据题意给出了四幅不同风格的画作,可以说,在图像生成上确实进步不少。
根据“双十一”生成一段视频,文心大模型4.0的回答如下:

不知道为何,文心大模型4.0也没能直接呈现出一段视频,只是根据指示词给出了一个视频脚本来,可能还有待进步吧。
四、记忆能力
最后一个维度就是十分重要的记忆能力。DoNews要求以“我喝了一口核污水”为开头写一篇小说。
文心大模型4.0的回答如下:

GPT-3.5的回答如下:

可以看到,在故事创造上,文心大模型4.0更偏重于结构框架,而GPT-3.5则偏重于故事内容。这让DoNews有一个大胆的设想,用文心大模型4.0写框架,用GPT-3.5填写内容,是不是就能得到一部完整的小说?
言归正传,DoNews继续提出增加人物背景、增加故事人物角色、增加冒险情节、丰富故事内容、增加具体情节等指令来。
文心大模型4.0的回答如下:
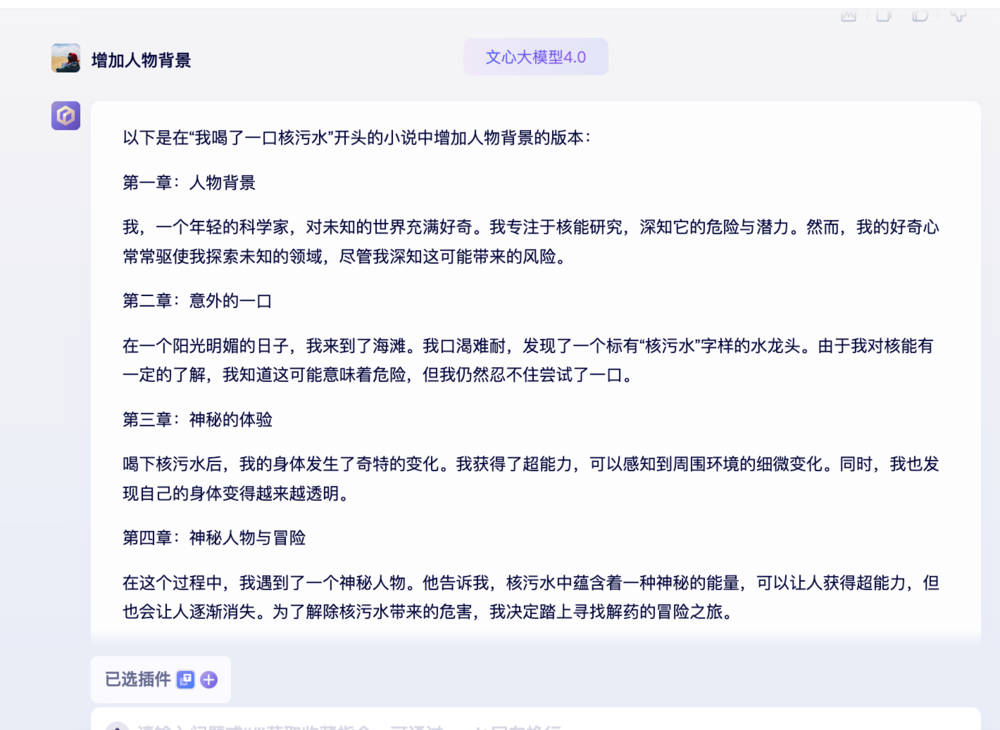
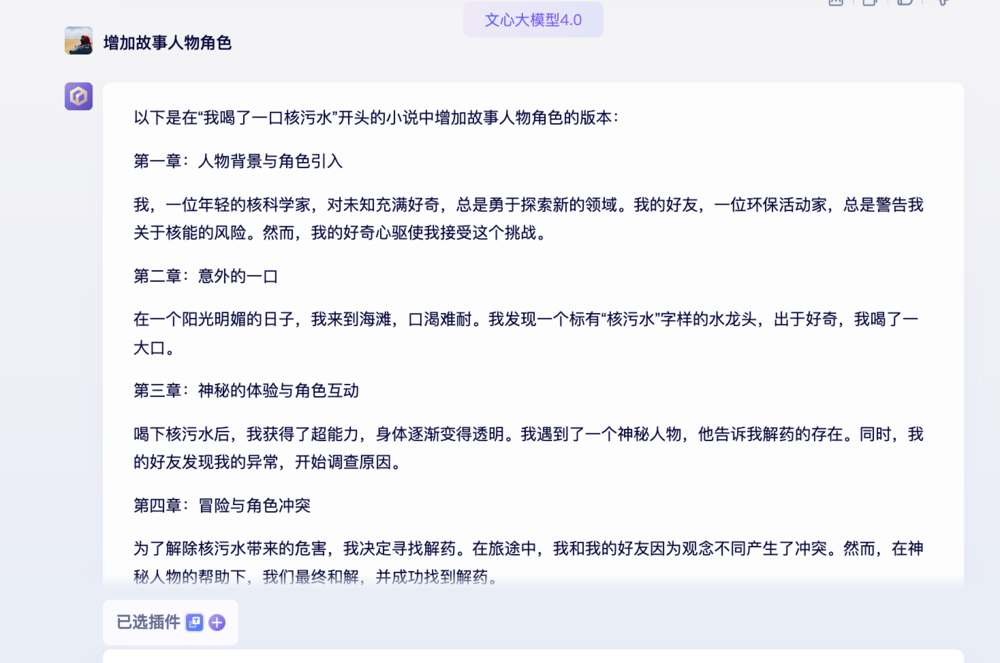

GPT-3.5的回答如下:
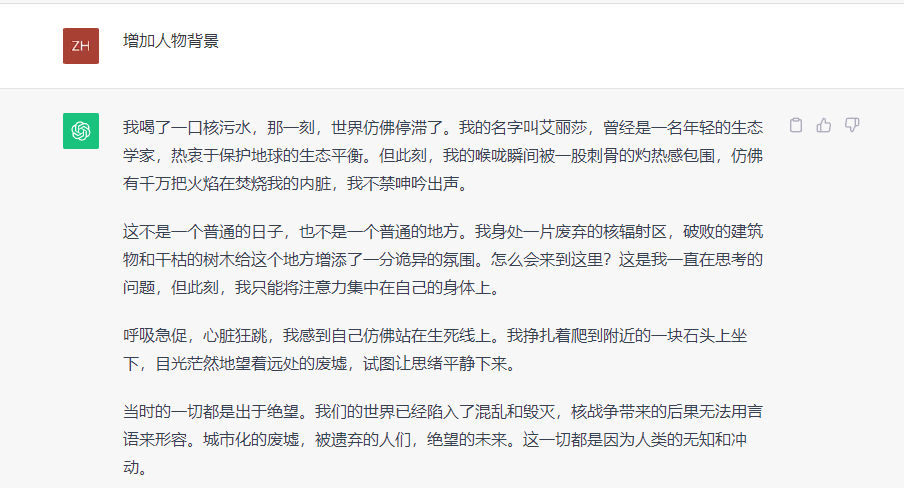

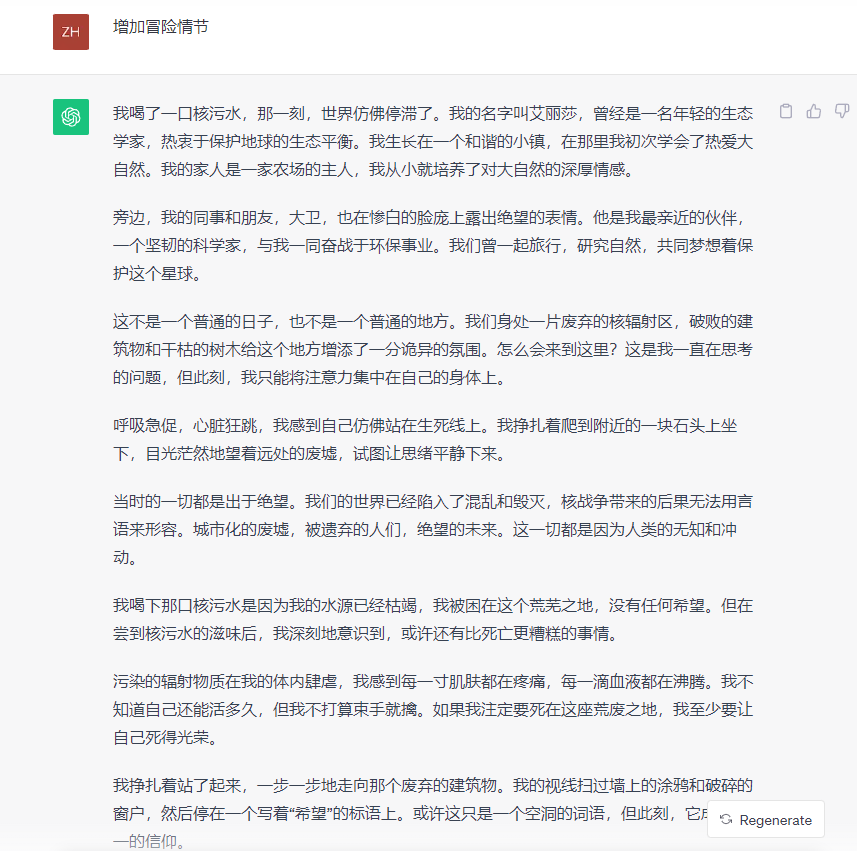
多轮问答后,文心大模型4.0和GPT-3.5都能根据给出指令适当增加内容,同时呼应之前给出的内容,但也会有一些细节遗忘,整体来看表现都不错。
结语:
根据测评结果来看,文心大模型4.0整体水平优于GPT-3.5,尤其在理解和生成两方面,表现令人惊喜。
大模型目前处于高速发展阶段,性能和应用效果都在不断提升,也曾一度引发了国内对于是否会在大模型领域落伍的担忧,不过从刚刚的对比结果来看,像百度文心这样的国产大模型同样表现优秀,即使会有差距,也是可以追赶,甚至是在短时间内追赶上的,大家不必杞人忧天。
相信未来,我们也将看到能力更强的国产大模型,在各行各业落地生根,便利我们的生活。






