
DoNews11月10日消息,来自微软 Azure 和微软研究院的一组研究人员推出了一个高效的 FP8 混合精度框架,专为大型语言模型训练量身定制。

经过测试,与广泛采用的 BF16 混合精度方法相比,FP8 混合精度框架内存占用减少 27% 至 42%,权重梯度通信开销显著降低 63% 至 65%。
运行速度比广泛采用的 BF16 框架(例如 Megatron-LM)快了 64%,比英伟达 Transformer Engine 的速度快了 17%。
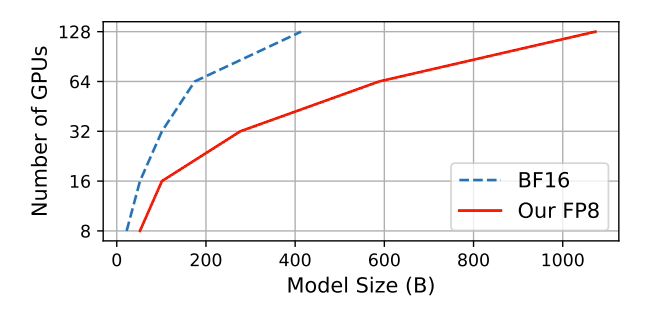
在训练 GPT-175B 模型时,混合 FP8 精度框架在 H100 GPU 平台上节省 21% 的内存,而且相比较 TE(Transformer Engine),训练时间减少 17%。






