
DoNews12月15日消息,据腾讯科技援引外媒报道,英伟达推出了新的Nemotron 3开源模型系列,包括Nano、Super和Ultra三个尺寸规格,并配套了相关数据集和技术,旨在构建高性能的专用智能体AI系统。
三个版本,定位分明
Nemotron 3 Nano:300亿参数,活跃参数量30亿,专为DGX Spark、H100和B200 GPU设计,专注于目标明确的高效任务,是该系列的效率先锋。
Nemotron 3 Super:1000亿参数,专为多智能体协同应用设计,强调高精度推理能力。
Nemotron 3 Ultra:约5000亿参数,具备庞大的推理引擎,面向最复杂的应用场景,提供顶级的推理能力。
Nemotron 3 Nano现已上市,为构建高吞吐、长上下文的智能体系统奠定了基础。
Super和Ultra版本将于2026年上半年推出,它们将通过更高的推理深度和注重效率的架构增强来扩展这一基础。
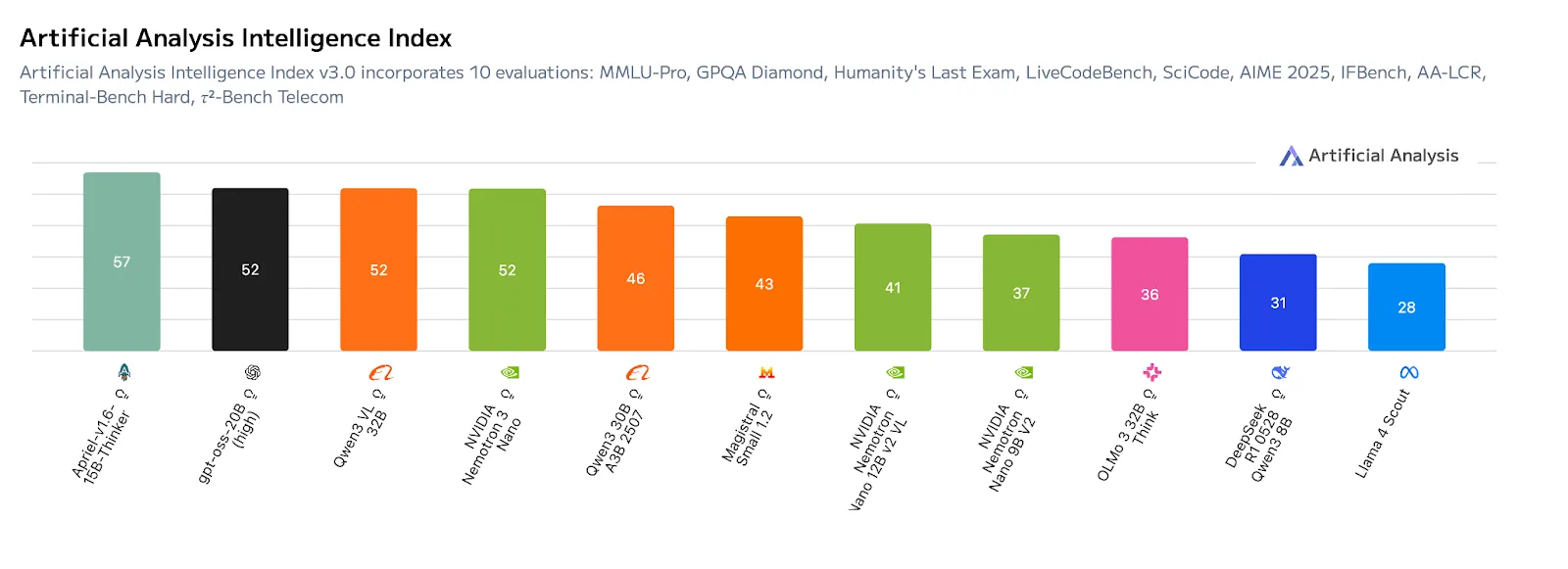
在Artificial Analysis Intelligence Index v3.0基准测试中,Nemotron 3 Nano在同等规模的模型中取得了领先的准确率得分(52分)。
三大核心技术,直指智能体痛点
为了支撑上述能力,Nemotron 3引入了三项紧密耦合的核心技术创新:
1.Mamba-Transformer MoE架构
该架构的创新之处在于将三种核心技术进行了深度融合:高效处理长序列的Mamba层、确保精密推理的Transformer层,以及实现可扩展计算效率的MoE(专家混合)路由机制。它们共同构成了一个高效协同的运算整体。
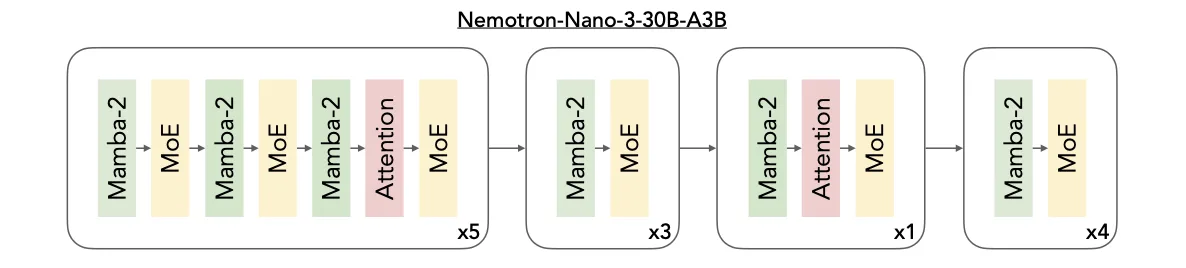
图:Nemotron 3采用混合架构,从而在最大化推理吞吐量的同时,依然保持了顶尖的准确性
Mamba层的核心优势在于能以极低的内存开销追踪长距离的依赖关系,即使面对数十万乃至上百万Token的超长序列,其性能依然稳定。这为处理长篇文档、复杂代码或持续对话提供了基础。
Transformer层则通过其精细的注意力机制,专门负责捕捉任务中深层的结构与逻辑。无论是代码的语法关联、数学公式的推导步骤,还是多步骤任务的规划依赖,它都能进行精准建模,为模型赋予强大的推理能力。
MoE组件的作用是在控制计算成本的前提下,智能地扩展模型的能力。其原理如同一个由众多专家组成的智库:对于每个输入的Token,系统只会动态调用最相关的一部分“专家”进行处理,而非动用全部资源。这种“按需调用”的模式,显著降低了运算延迟,并大幅提升了整体吞吐效率。
正因如此,这套混合架构天然适配需要高并发处理的多智能体场景。想象一个由众多轻量级AI助手组成的集群:它们可能同时在生成任务计划、分析上下文信息或调用各种工具执行工作流。该架构能够为每个并发的智能体实例提供高效、独立的计算支持,从而确保整个系统流畅、敏捷地运转。
2.多环境强化学习训练
为了让Nemotron 3的行为模式更贴近能够解决实际问题的智能体,英伟达在发布前对其进行了关键一步的“实战演练”,在名为NeMo Gym的开源强化学习平台中进行后训练。
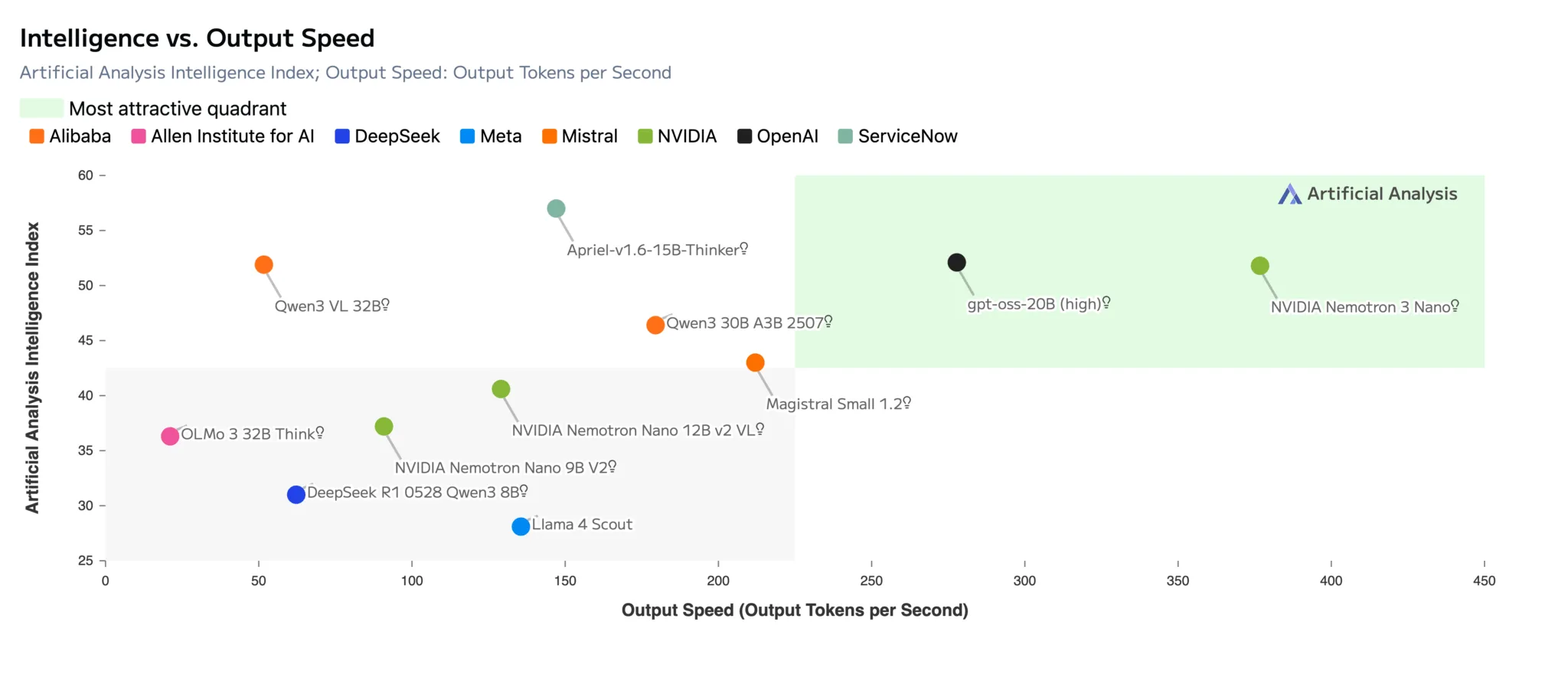
图:Nemotron 3 Nano凭借其混合专家(MoE)架构实现了最高的吞吐效率,并通过在NeMo Gym平台上的强化学习训练,获得了领先的推理准确度
这个平台提供了多种模拟现实世界的虚拟环境。在这些环境中,模型不再仅仅是回答单个问题,而是被评估其执行一连串复杂动作的序列能力。具体任务可能包括:准确调用一个应用程序接口来查询数据、编写一段能真正运行并解决问题的代码,或者构思一个包含多个阶段、且最终结果可被验证的详细计划。
这种基于完整行为轨迹的强化学习训练,其核心目标是让模型“学会思考”,从而在真实的应用中表现得更稳定可靠。它能有效减少模型在长链条任务中可能出现的“推理漂移”(即思维逐渐偏离正轨),并提升其处理具有固定逻辑和结构化步骤的任务流程的能力。
一个经过这种训练后变得“可靠”的模型,在实际部署时,更不容易在执行中途“卡壳”或做出前后矛盾的决策。同时,这极大地降低了将前沿大模型转化为解决具体领域问题的“专家智能体”的门槛和成本。
3.100万Token上下文窗口
Nemotron 3的100万Token上下文窗口,使其能够将完整的任务背景、历史记录和复杂计划保存于单一“工作区”,实现真正意义上的长程、持续推理。这消除了因传统文本切割导致的信息碎片和逻辑断层。
其实现得益于核心的高效混合Mamba-Transformer架构,它能在低内存开销下处理超长序列,而MoE(专家混合)路由机制则通过按需激活专家,将处理庞大上下文所需的实际计算量控制在可行范围内。
对于企业级的深度文档分析、跨会话智能体协作或整体代码库理解等复杂任务,这一能力能直接提升事实准确性、保障逻辑连贯性,是构建可靠、持久AI应用的关键基础。
即将推出的关键技术
为了在更大规模的Super和Ultra版本中实现更强的性能与效率,Nemotron 3引入了三项进阶的关键技术:
潜在MoE:用相同成本调用更多“专家”
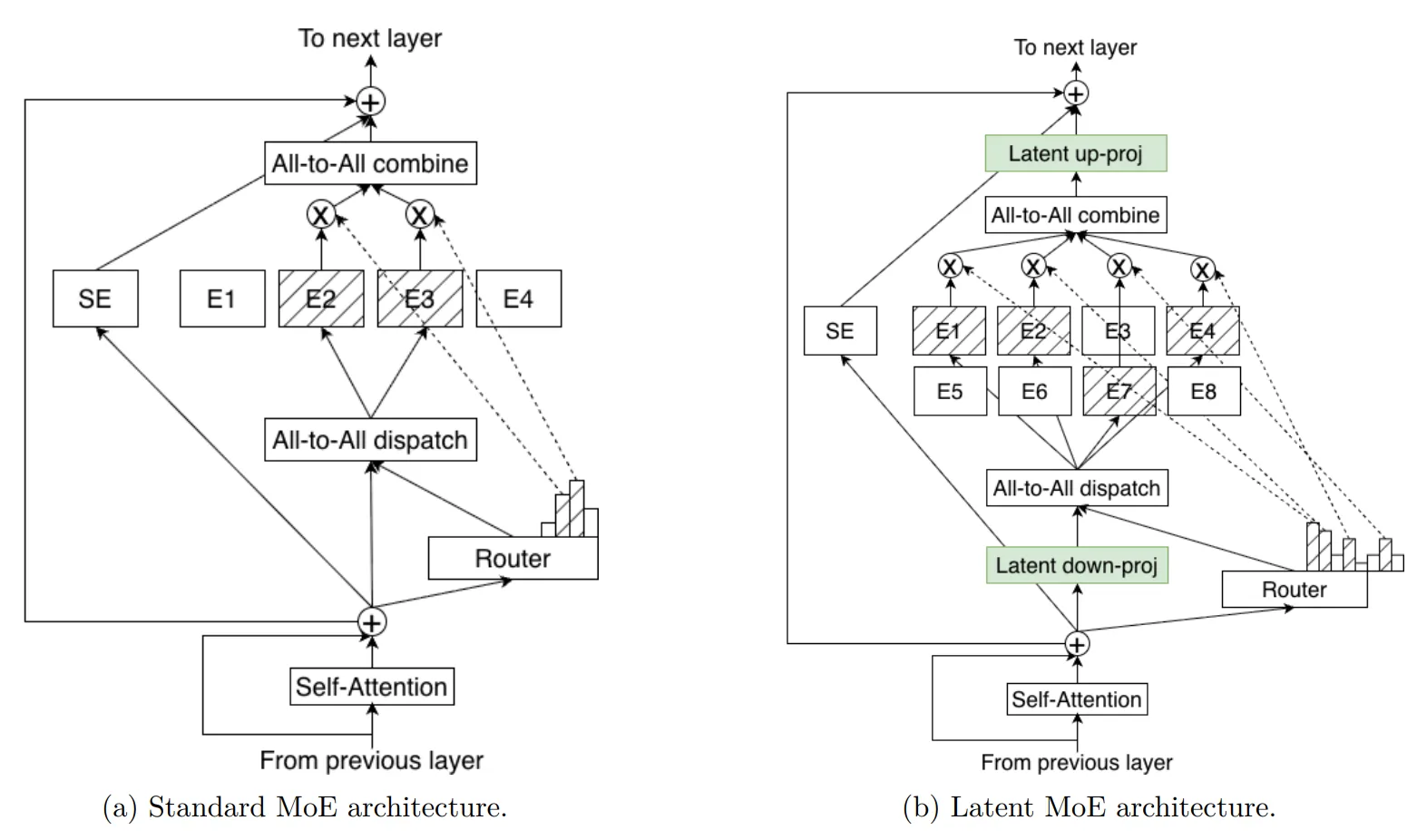
图:标准MoE与潜在MoE架构对比
Nemotron 3 Super 和 Ultra 采用了潜在MoE技术。在此设计中,模型的各个“专家”模块并非直接处理原始的Token数据,而是先在一个共享的、维度更低的潜在表征空间 中进行运算,再将结果转换回Token空间。
这种设计的精妙之处在于,它能让模型以基本相同的推理计算成本,动态调用多达4倍的专家数量。这相当于在不增加“脑力”负担的情况下,显著扩充了可用的“专业智库”,使模型能够对更微妙的语义差异、特定领域的抽象概念,以及需要多步推导的复杂推理模式,实现更精细、更专业化的处理。
多Token预测:一次生成多个词,提升响应速度
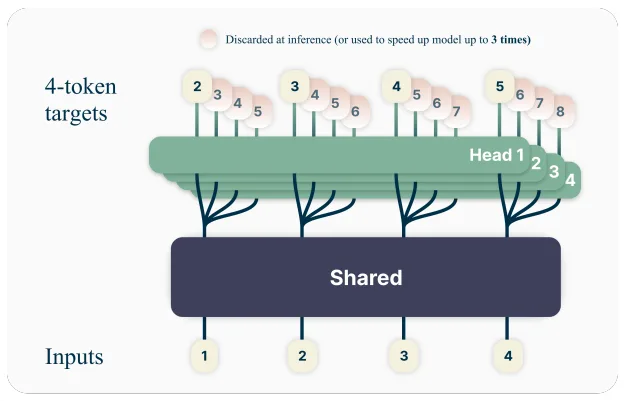
图:多Token预测技术允许模型在训练时同时预测未来多个Token,显著提升模型的响应速度
多Token预测技术改变了模型逐词生成的惯例,允许其在一次前向计算中,同时预测后续的多个Token。这对于需要生成长篇逻辑推理(如思维链)、结构化输出(如代码、JSON)或未来行动轨迹的任务而言,能显著提高生成吞吐量。
其效果直观体现为:在规划、代码生成或长对话等场景中,智能体的响应延迟更低,整体反应更为敏捷流畅,极大地改善了交互体验。
NVFP4训练格式:高精度与低成本的平衡
Super和Ultra模型的预训练使用了英伟达自研的4位浮点格式NVFP4。该格式的核心价值是在训练与推理的成本与模型精度之间实现了业界顶尖的平衡。
专为Nemotron 3优化的NVFP4训练方案,确保在25万亿Token数据集上,训练过程既能保持稳定,又能保证最终模型的准确性。在实际训练中,绝大部分的浮点乘累加运算都在NVFP4格式下高效完成,从而在控制巨量计算开销的同时,锻造出高性能的模型。
开源Nemotron训练数据集
英伟达还将发布用于模型开发全过程的开放数据集,为如何构建高性能、可信赖的模型提供了前所未有的透明度。
新发布的数据集包括:
Nemotron-预训练集:一个新的包含3万亿Token的数据集,更广泛地涵盖了代码、数学和推理内容,并通过合成增强和标注流程进行了优化。
Nemotron-后训练集 3.0:一个包含1300万样本的语料库,用于监督微调和强化学习,是Nemotron 3 Nano实现对齐和推理能力的动力来源。
Nemotron-RL数据集:一套精选的强化学习数据集和环境,用于工具使用、规划和多步推理。
Nemotron智能体安全数据集:一个包含近1.1万条AI智能体工作流轨迹的集合,旨在帮助研究人员评估和缓解智能体系统中新出现的安全与安保风险。
结合英伟达的NeMo Gym、RL、Data Designer和Evaluator等开源库,这些开放数据集使开发者能够训练、增强和评估他们自己的Nemotron模型。
英伟达生成式AI软件副总裁卡里·布里斯基表示,公司希望展示其从前代模型中学习与改进的承诺。“我们相信,我们具备独特的优势,能够服务广大开发者,他们希望通过结合我们新的混合专家模型架构和100万Token的上下文长度,来获得完全定制模型、构建专用AI的灵活性。”布里斯基说道。
英伟达表示,Nemotron 3模型的早期采用者包括埃森哲、CrowdStrike、Cursor、德勤、安永、甲骨文云基础设施、Palantir、Perplexity、ServiceNow、西门子和Zoom等公司。






