
AI像火焰,正在吞噬世界,而算力构成了“柴薪”。在国与国之间的人工智能竞争日益激烈的当下,算力成为国力的重要体现。
围绕着这个话题,不久前,华为在北京组织了2026新春媒体沙龙。目前,计算产业已经成为华为公司最重要的业务主航道之一,华为计算产品线营销运作部部长张爱军表示,希望未来为中国构建一个坚实的算力底座,“为世界提供一个新的选择”。
“超节点”成为他演讲的关键词。
什么是超节点?
超节点在行业内还是一个新生事物,行业内对超节点还未形成标准定义,张爱军表示,华为希望在行业界形成共识,定义什么样的设备是超节点。
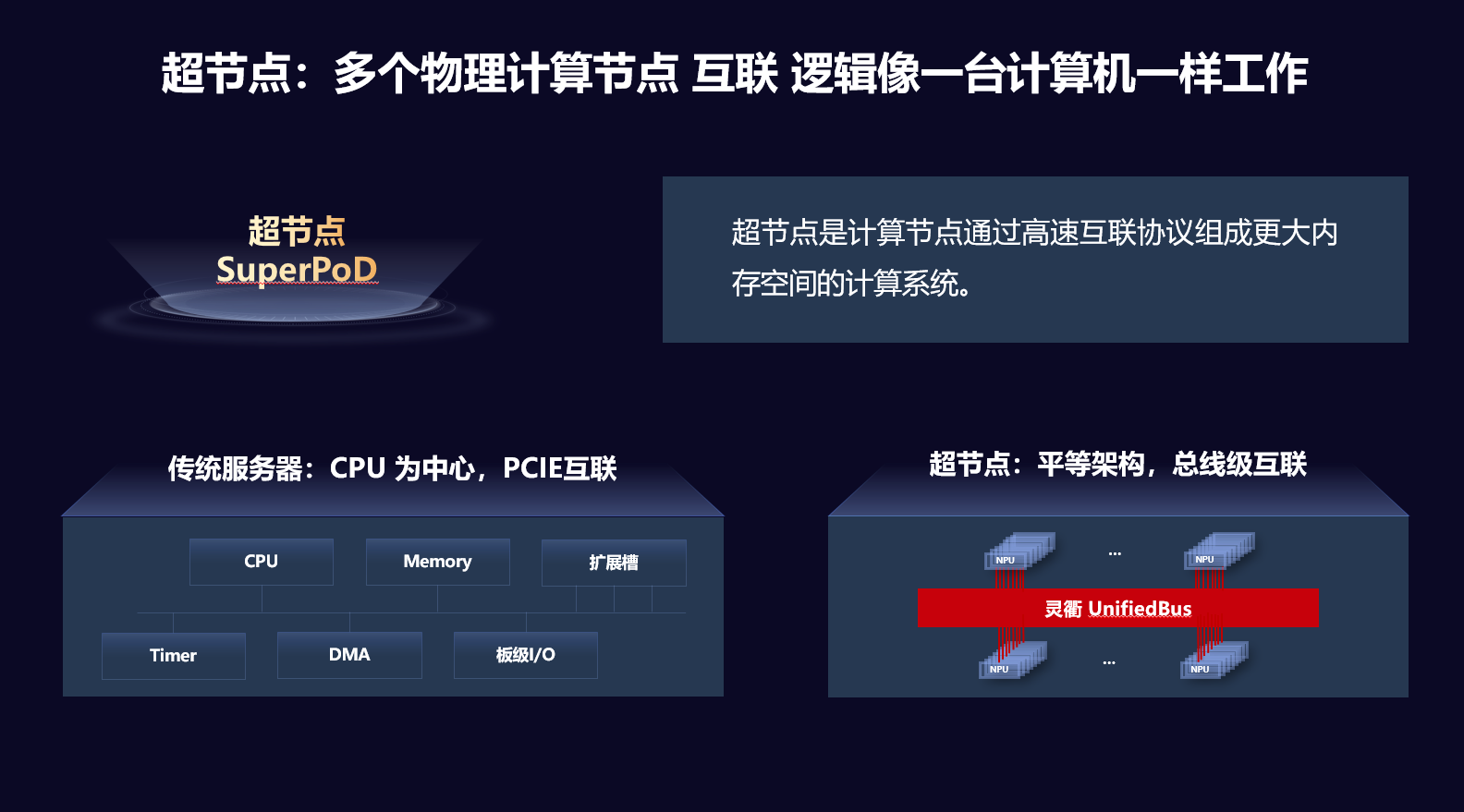
目前业界有些看法,认为超节点类似“大型机”,或者连接的计算卡足够多,就是超节点了。张爱军认为这些看法是对超节点的误解,从华为的角度来说,“超节点”是计算节点通过高速互联协议组成更大内存空间的计算系统,能够提供大带宽、低时延的互联能力。
传统计算架构中,卡间互联依赖PCIe或以太网,跨服务器互联带宽多为200-400Gb/s且时延达数十微秒,在千亿参数模型训练的并行计算场景中,频繁的GB级数据通信阻塞,导致计算等待通信,成为性能瓶颈。
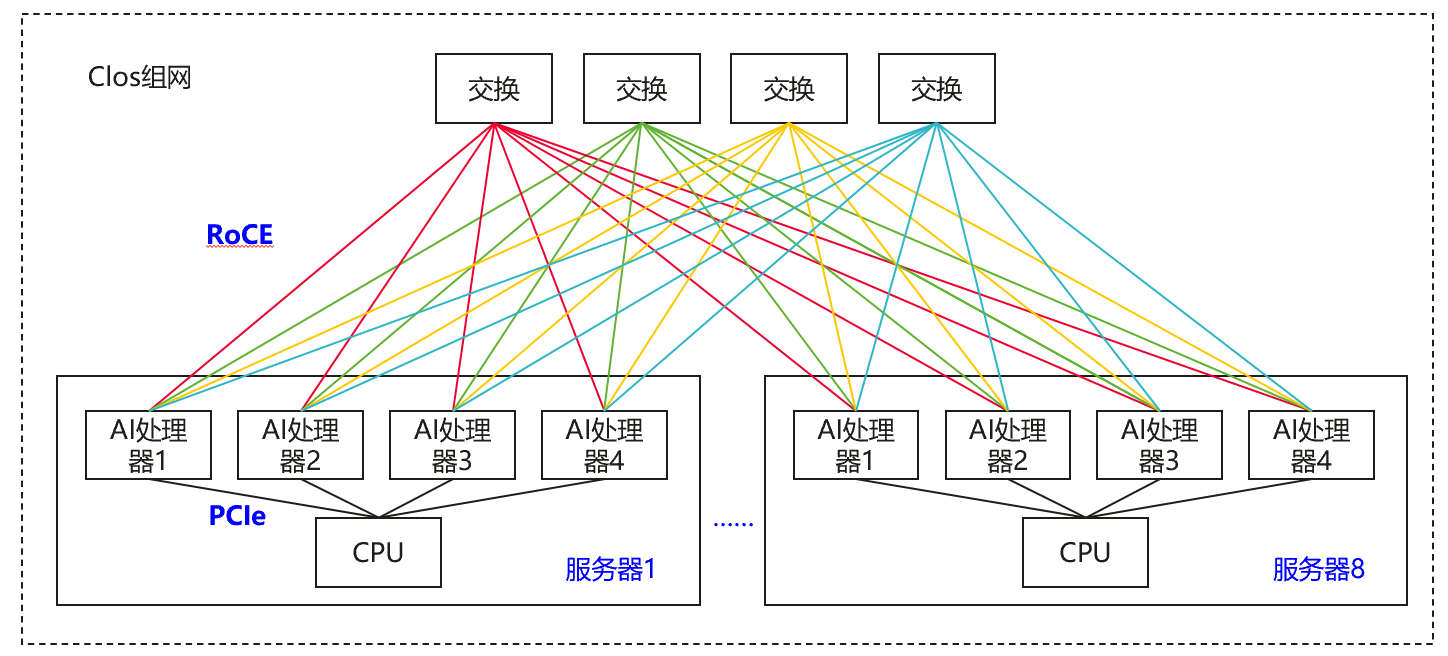
比如下图中,CPU-AI处理器之间通过PCIe互联,AI处理器之间通过RoCE互联,单跳通信时延只能做到微秒级,RTT通信时延会更高,高达几十微秒;假如要从32卡升级到64卡规模,需要增加二层交换,组网复杂;而且不支持内存统一编址,无法做到全局的内存池化以及AI处理器之间的内存语义访问,所有访存都需要通过消息语义通信,优化存在瓶颈。
而超节点借助高效的互联协议打破传统架构限制,能做到大带宽、低时延、内存统一编址,支持更大规模AI处理器的高效协同,实现更大范围、更高流量的数据传输,从而突破系统性能瓶颈。
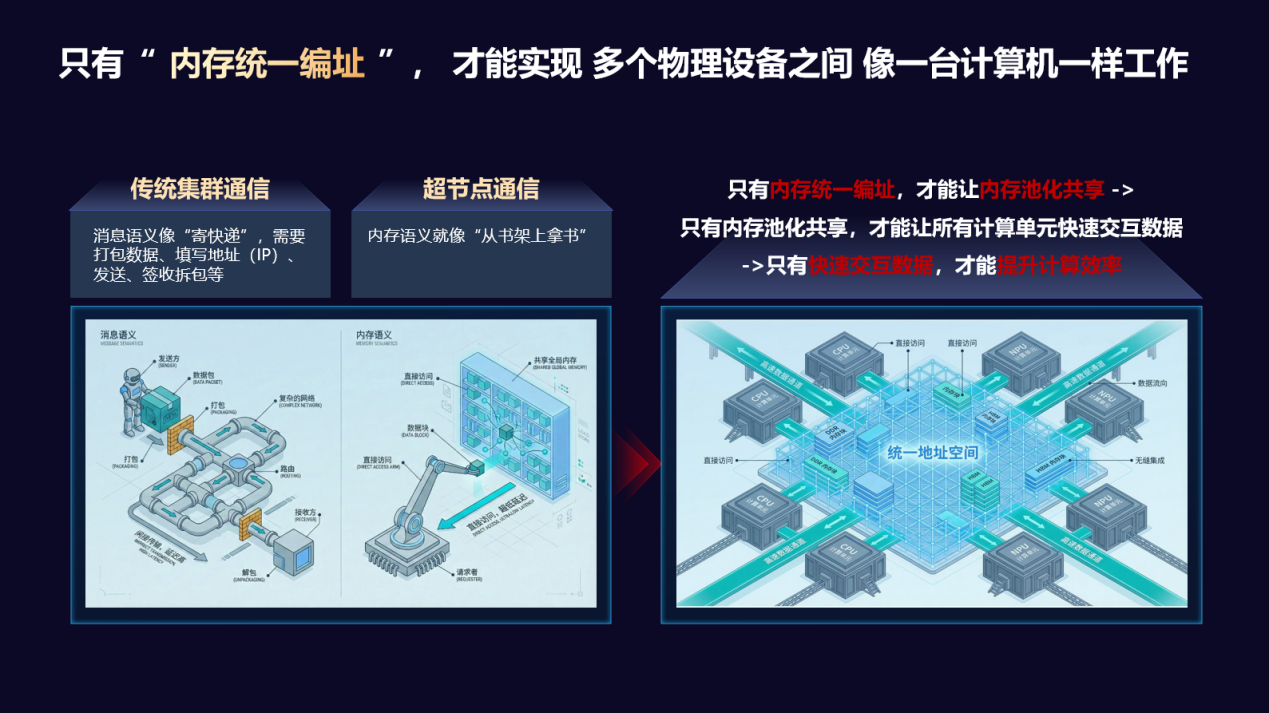
张爱军做了个比喻:“有足够大的带宽,就像中国的经济为什么能够腾飞,基础设施包括高速公路、高速铁路功不可没,一个好的超节点一定要有足够大的带宽;高速公路路修得宽,还不能堵车,要有足够低的时延,长安街也很宽,但是经不起天天堵,时延不足够好很难构建起来效率;能不能形成有效的逻辑上的单一系统,关键是内存能不能真正统一编址,有统一内存编址的技术才能真正称得上超节点。”
以昇腾384超节点为例,相较于传统服务器架构,通信带宽提升15倍、RTT通信时延从7微秒做到3微秒,降低了50%以上。
现实情况中,还需要具备散热技术、模块化架构、冗余能力、连接技术、供电能力等工程能力,以及大规模、高可靠、灵活切分等系统能力,才是真正可商用的超节点。
为什么需要超节点?
超节点的出现,是AI发展的必然产物。
张爱军在演讲中提出了三个趋势观察:
首先,模型的规模正变得越来越大。人工智能的核心在于压缩与泛化,压缩是通过计算将物理世界的多元信息映射为函数表达,这一过程需消耗大量算力,随着大模型从单模态转向多模态,其对算力的需求会进一步上升。
其次,输入长度显著增加,模型上下文长度,将从K级迈入兆级。进入多模态时代,输入从文字到加入视频和图片,导致序列长度大幅提升,在计算过程中更长的输入意味着更长的矩阵维度,进而推高计算量。
第三,在数据层面,泛化能力决定了智能上限,而提升泛化离不开更多数据,利用人工智能生成合成数据以持续扩展训练资源已成为趋势,训练数据规模也从 10TB 级升级为 100TB 级。
“所有的一切都决定了未来对算力的需求会指数性增长,,今天算力的需求远远未被满足,无论是在行业里进入到生产系统的过程当中,还是在ToC的消费端,我们看到token消耗的数量不是倍增,而是指数级增长。去年国家数据局发布的数据,2024年初,我国每天消耗的AI相关“Token”(可理解为AI处理的基础数据单元)只有1千亿;可到了2025年6月底,这个数字已经突破30万亿,短短1年半时间就涨了300多倍。”张爱军说道。
但当我们将视线移向算力的供给端,随着半导体制造技术接近触及物理极限,摩尔定律正在失效,导致单一芯片的提升难以满足人类对算力的需求。这种情况下,多芯片互联的大规模计算节点就成为解决问题的关键。
这就回到了上文中提到的问题,传统集群通过“服务器堆叠和以太网联接”的模式提升算力规模,服务器之间带宽不足、时延大,集群规模越大,算力利用率反而越低。Meta公布的Llama 3.1论文显示,在1.6万卡H100集群上训练时,算力利用率低。同时,集群规模扩张还带来了可靠性问题,在54天的训练过程中,整个集群累计中断419次,平均每天中断8次,也就是说每3小时就会出现一次故障。
此外,在推理端,对低时延的要求日益严苛。比如金融风控场景时延要求小于20毫秒,反欺诈的时延更是要在10毫秒以下。而Agentic AI需要更多任务协同和多轮次推理迭代,传统的计算架构也难以满足低时延要求。
因此,超节点应运而生,通过新的互联协议及架构突破服务器扩展的硬件限制,来增强算力的供给。经华为验证,在DeepSeek、Qwen等多模态、MoE模型上,超节点相较于传统集群可以达到3倍以上训练性能的提升,同时在强化学习场景下,可以将训推权重的传输从小时级降到60s。
华为的算力攻坚
2019年,华为进入计算产业,当时提出了“硬件开放、软件开源、使能伙伴、发展人才”的十六字方针。时隔六年,鲲鹏的注册开发者数达到了约380万,昇腾约有400万,同时,华为还和约9800家ISV伙伴打造了超过2万个解决方案,这些解决方案广泛应用在金融、运营商、能源、制造等领域。

但比起数量的增长,真正的攻坚源于底层技术的突破,以及新技术的成功商业化,超节点就是这样的一个案例。
采访中,张爱军提到了一个细节,光模块是比较“娇嫩”的系统,灰尘、温度变化都会导致系统的闪断和不稳定,而华为昇腾384的超节点光模块有将近几千颗,通过模块化的设计和冗余技术等,实现了规模化的商用。
据了解,自去年正式上市以来,昇腾已经规模部署了将近数百套,广泛应用在互联网、金融、能源、制造等各行各业中。
过去一年,华为还在业界首创了将超节点技术引入到通用计算中,是全球第一家发布了通算超节点的厂商。华为还将构建超节点的灵衢协议完全开放,以推动在中国形成完整的产业链模式。
当天受邀参加活动的工业和信息化部新闻宣传中心(人民邮电报社)总编辑王保平在会议开始时讲道:“算力作为数字经济的核心生产力,已经成为像水电一样的基础资源。当前算力需求从通用计算向智能计算延伸,从中心向边缘扩展,这既需要芯片、服务器、数据中心等硬件领域的持续突破,也需要架构软件、调度平台等系统层面的协同创新。”
而华为,在这个历史进程中,做出了重要的推动。
面向未来,张爱军表示,就像在移动互联网时代,华为给世界提供了领先的5G产品,面向未来AI时代,华为将通过“集群+超节点”的创新,为中国包括全世界提供算力新选择。






