

撰文 | 雁 秋
编辑 | 李信马
题图 | 豆包AI
AI圈盼DeepSeek-V4久矣!
自从2025年初发布V3以后,DeepSeek断断续续发布了几个没什么火花的版本:V3.1、V3.2-Exp,跑分都和前代差不多。
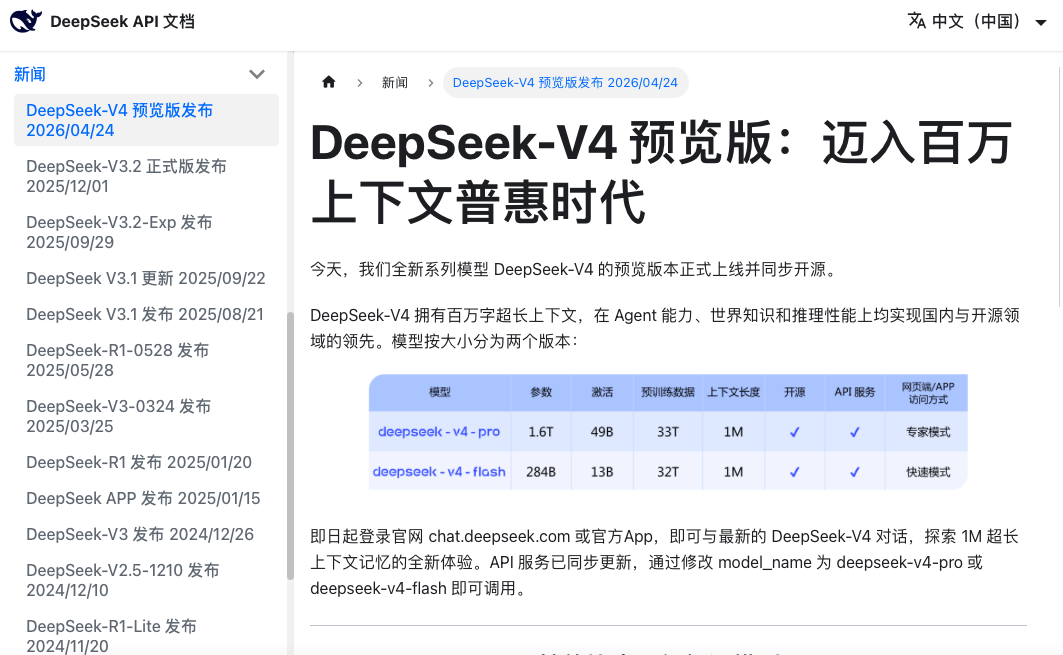
直到4月24日,DeepSeek正式开源DeepSeek-V4预览版,同步推出 V4-Pro与 V4-Flash两大版本。
-
V4-Pro,总参数1.6万亿,每次推理激活490亿。定位旗舰,对标顶级闭源模型。
-
V4-Flash,总参数2840亿,激活130亿。定位经济,更小更快。
图源:DeepSeek官网
“源神”回归瞬间刷屏,不仅登上科技热榜,华丰科技、寒武纪、摩尔线程、中芯国际等概念股更是直线拉升。
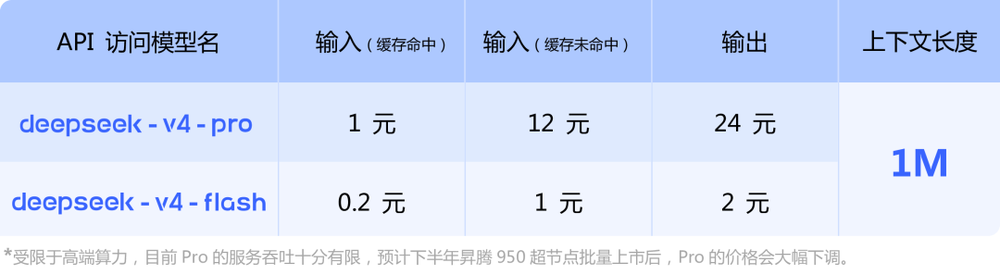
官方公布了DeepSeek-V4系列的API定价:
V4-Pro在输入命中缓存的情况下为1元/百万tokens,输入未命中缓存则为12元/百万tokens,输出为24元/百万tokens;
V4-Flash在输入命中缓存仅0.2元/百万tokens,未命中输入1元/百万tokens,输出2元/百万tokens。
图源:DeepSeek官网
然而,高端算力短缺,是顶级大模型落地的最大瓶颈。对此,DeepSeek表示:V4-Pro服务吞吐十分有限,预计下半年昇腾950超节点批量上市后,价格会大幅下调。
一句“下半年批量上国产算力”,揭开了以昇腾950为核心的国产算力生态发展趋势——从「备选」走向「刚需」,成为重构AI成本的关键力量。
DeepSeek此前的训练主要依赖英伟达,但随着美国对华芯片出口管制升级,中国AI算力面临高强度的压力——迫切需要原生的、可自主掌握的芯片。
观察发现,V4技术报告第3.1节专门写了一句,「我们在英伟达GPU和华为昇腾NPU两个平台上均验证了细粒度EP(专家并行)方案。」
这是DeepSeek官方第一次在正式文档中,把昇腾和英伟达并列写进硬件验证清单。业内推测,部分训练大概率用的还是英伟达芯片,但在与昇腾的适配上,它显然达到了前所未有的“原生”水平。
根据IDC最新报告,2025年国产GPU与AI芯片厂商的市场份额攀升至41%,总出货量约400万张。其中,昇腾出货量排名第一,占总量近半,阿里平头哥紧随其后,百度昆仑芯、寒武纪并列第三。此外,海光信息、沐曦、天数智芯等厂商稳步放量,成为紧紧跟随的第二梯队。
顶尖模型正在适配国产算力、生态协同初现雏形。
01、抓住算力主权
昇腾与英伟达有着相似的成长轨迹,都是在试错与迭代中摸爬滚打。
但双方始终有个核心差异:英伟达的根基是GPU与CUDA架构,而昇腾CANN选择完全自主研发的NPU,从运行、驱动、虚拟指令集到编译器 ,每一个核心环节都掌握在自己手里。
这一选择的意义在于,从根源上避免成为CUDA生态的附庸。
昇腾的自我革命首先从芯片开始。据公开信息,昇腾早期产品在算力配比、编程灵活性、细粒度访存能力、低精度格式支持及社区参与度等方面存在不足。
经过一系列芯片架构的大幅调整,2026年3月的合作伙伴大会上,成果终于揭晓:
搭载昇腾950PR处理器的Atlas 350加速卡,单卡FP4算力达1.56P,为英伟达H20的2.87倍;HBM容量112GB,较H20提升16%;内存访问粒度从512字节压缩到128字节,小算子访存效率提升4倍。
同时,昇腾实现了国内首个真正意义上的FP8商用。这意味着,在市场智能体爆发、Token处理量激增的节点,可以用更少的算力干更多的活。
据悉,2025年DeepSeek采用英伟达产品实现FP8创新时,昇腾团队“羡慕得不得了”,但因相关限制无法及时推出对应产品。如今,市场对新一代昇腾950芯片的接受速度超出了不少人的预期。
但需要注意的是,950在特定情况下,单卡推理能力是英伟达H20的近3倍,但在整体性能上,英伟达仍处于旗舰水平。未来昇腾会选择特定场景优化,还是全面对标旗舰?
对此昇腾方面给出了明确回应,昇腾做的是通用型产品,芯片架构也一直在向更通用的方向改进,“但每一代芯片都有确定性的改进方向,而不是追求每个方面都有巨幅提升。”
950的升级获得了客户的反馈积极,从试用到下单的周期大幅缩短。“以前需要一两个月才考虑下单,现在一个星期就可以。”据昇腾内部人士透露,这得益于产品成熟度的提升,和当前旺盛的市场需求,“在来北京的前一天,还有客户专门跑去深圳找我们签单,都是千万卡起步。”原本过完年就已售罄的产能,如今正在重新拉高供给线。尽管如此,团队方面仍保持谦逊:“950并不完美,还有很多事要做。”
一个美好且正向的闭环出现:国产算力规模越大、成本越低,模型服务价格就越低,开发者的采用意愿就越高,从而带动更大的算力需求。
随着这个循环成立,昇腾将成为中国AI绕开CUDA依赖、走向自主加速的核心驱动力。它也不再只是“能用”的替代品,而是开始建立“好用”的竞争力。
02、生态重构:把“麻花团”拆开
过去几年,即便是昇腾内部也承认,CANN生态的开放度和易用性远远不够。昇腾的软件体系如同 “⿇花团” 般纠缠在一起 ,升级时牵一发而动全身 ,极大影响开发者体验。
昇腾的打法是:底层我自主,上层全兼容,架构拆开,核心开源。目标很明确,让开发者来了就不想走,更愿意一起玩。
想要达到这个目的,需要填平的不是技术断层,而是长期积累起来的使用习惯和信任差距。让90多个以海外团队为主导的开源项目接纳中国硬件作为原生支持,远比想象中困难,昇腾团队的办法是靠技术语言说话,亲自前往开源社区现场交流,用能力证明自己。
昇腾做了一件近乎“自我开刀”的事——重新设计架构、 重写软件,完成架构解耦与独立升级,将复杂体系拆分为一个个结构化模块,每个模块可独立更新、独立开源。为了让开发者 “不换门 、不折腾” ,昇腾全力推动生态兼容 ,主动融入主流开发体系,开发者若对某个模块不满意 ,可自主修改、优化。
据了解,整套工作原计划一年半完成,最终压缩至四个月。目前,开源仓库从最初的20多个涨到70多个,外部伙伴和高校的项目也在往里进。为了避免变成“一言堂”,社区的技术指导委员会硬性要求外部成员不低于50%,每月开会,前前后后开了200多次,规则一起定,路一起走。
开发者是生态的核心活力来源,昇腾现在有1.3万底层算子开发者,这个数字已经跟英伟达同领域的万级规模看齐。社区月活跃开发者2000人,作为偏底层的项目,比PyTorch社区的900多月活还高。
对于如何吸引习惯于CUDA生态的开发者,昇腾方面认为没有什么绝招:“就是看你做得好不好,对开发者有没有价值,哪个更能实现你的需求,你就选哪个。”
昇腾内部强调,客户的成功是华为成功的前提。“能支持他拼过同行,你就有了优势。客户转了一圈回来说‘还是你们最好’,就是这个道理。”在AI这个没有标准、快速变化的赛道,不存在“压制”,拼的是第一时间支持新模型、快速解决安全等后顾之忧的能力。
“生态是一个‘量’的问题。没有销售量和使用量,谈生态就是空谈。”昇腾一位负责人直言,“我把外部开发者等同于‘不要钱的员工’,让他们真正成为生态体系的一员。”据透露,他们已准备好2000万激励资金,“希望开发者们快点给我花完,最好这个季度花完,下个季度我再发2000万。”
未来极有可能出现一种趋势,上层软件和开源社区的特性都是基于昇腾原生的。“这是我们的目标,现在要做的就是维持在95%以上,把分母中加上越多我的东西越好。”
尾声
DeepSeek-V4的发布稿最后写了这样一句话:「不诱于誉,不恐于诽,率道而行,端然正己。」
这句话出自《荀子·非十二子》,意思是不为虚名所诱惑,不因诽谤而恐惧,遵循道义行事,端正自身行为。
这种态度,放在这些年的AI圈尤为珍贵。浪潮一波接一波,先是ChatGPT横空出世,后有DeepSeek惊艳亮相,再到2026年初Agent(智能体)的全面爆发,每一次技术浪潮似乎都为行业带来了“泼天的富贵”。
但机会的天降也掩盖了产品内在的不足。昇腾走过弯路,也被市场的“泼天富贵”掩盖过问题,关键是要能从热潮中识别出产品改进点,持续投入,自我迭代。
面临外部的制约,昇腾直面最根本的问题——芯片与生态。在他们看来,任何试图单纯在软件层面模仿CUDA的行为,本质上都是在为英伟达的生态“添砖加瓦”,一旦紧急情况发生,所有软硬件都将瞬间“全废”。
回过头来看,昇腾的自主路径走得不算快,但却很踏实。这正是荀子所说的做人做事的态度,专注于做正确的事,而非活在别人的评价里。






