
DoNews5月20日消息,在今日的 2026 谷歌 I/O 开发者大会上,谷歌发布了包括Gemini全家桶在内的诸多新品。以下是 Google CEO Sundar Pichai 在 Google I/O 2026 大会上的讲话编辑稿,经调整以包含更多在舞台上宣布的内容。

自上一届 I/O 大会以来,我们度过了非常充实的一年。在这期间,我们保持着高频的产品发布节奏,见证了技术的不断突破与飞速进展。如今,用户越来越希望在日常使用的产品中,切实感受到 AI 带来的实际价值。我们一直专注于此,你将通过我们今天在 I/O 大会上发布的产品和功能中看到这一点。
迄今,公司“AI 优先 (AI-First) ”的转型已有十年,我们始终坚信,发展 AI 是践行公司使命、大规模改善人们生活最有效的方式。正因如此,我们才坚持走一条独有的全栈式 AI 创新路线:从定制芯片、安全稳固的基础框架,到世界一流的研究与基础模型,再到触达全球数十亿用户的产品和平台。这种方式让我们能以更快的速度进行迭代与创新,并为公司的全线业务注入强劲动能。
令人欣喜的是,全球用户正在以多种方式使用 AI:学生们正利用 Gemini app 准备期末考试;音乐家和艺术家将 Lyria 和 Veo 等生成式 AI 模型融入到自己的日常创作中;开发者也在使用 AI 编写代码,将想法转化为现实。
全栈式 AI 发展势头
用户在日常场景中如何使用 AI,是衡量技术进步的最佳标准。而要理解用户采纳 AI 的实际规模,还有一个非常直观的量化指标——token。Token 是我们的模型处理数据的基本单位,许多 token 代表着一个被解决的问题。
两年前,我们在各个产品平台上每月处理的 token 量为 9.7 万亿个,这已经是一个庞大的数字。在去年的 I/O 大会上,这一数字增长到了约 480 万亿个。而到今天,这一规模同比实现了 7 倍的巨幅增长,每月处理的 token 量已一举突破 3200 万亿个。
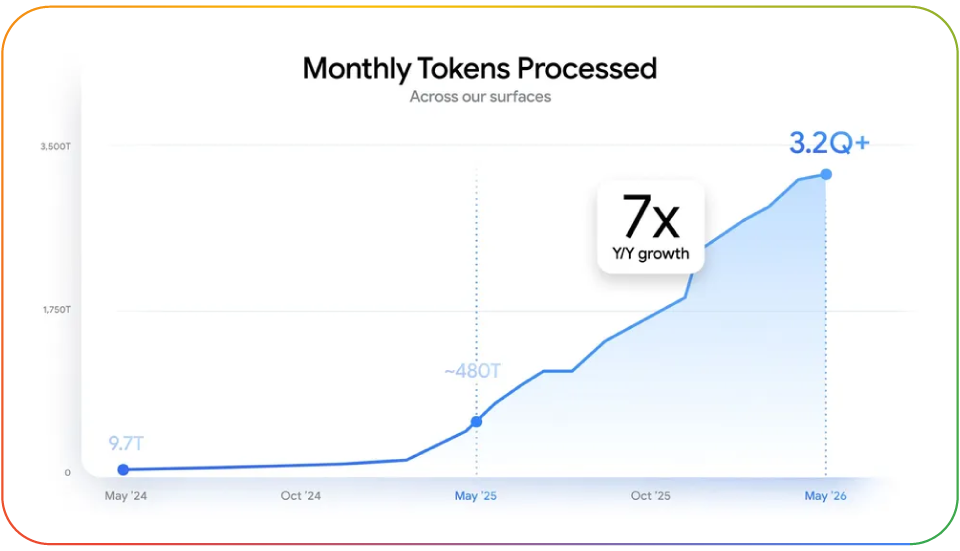
这一数据清晰地反映了我们的产品以及整个开发者和企业生态的发展:
目前,每月有超过 850 万名开发者正在使用我们的模型构建全新的应用与互动体验。
我们的模型 API 当前每分钟处理的 token 量已高达约 190 亿个。
在过去 12 个月中,有超过 375 家 Google Cloud 企业客户各自处理了超过 1 万亿个 token,这展现出各行各业对 AI 的强劲需求。
产品的增长势头
目前,Google 旗下已有 13 款产品各自拥有超过 10 亿的用户规模,其中更有 5 款产品的用户数量超过了 30 亿。Gemini 模型正是吸引更多用户使用、并提升用户活跃度的核心驱动力。
一切都始于搜索,在让更多用户体验到生成式 AI 的优势这件事上,它的贡献超过全球任何其他产品。目前,AI 概览 (AI Overviews) 的月活跃用户数已超过 25 亿。
而搜索的 AI 模式 (AI Mode) 更是有史以来最重大的升级。该功能深受用户喜爱,在推出一年内,其月活跃用户数就已经突破了 10 亿大关。
当用户在搜索中体验到这些 AI 驱动的功能后,他们使用搜索的频率更高了。搜索不再仅仅是简单的一问一答,而更像是一场连续的对话,它协助用户获取更深层的洞察,并无缝连接互联网上的海量信息。
同时,Gemini app 也在飞速创新。在去年 I/O 大会时,Gemini app 的月活跃用户数为 4 亿。而今天,这一数字已突破 9 亿,在一年内增长幅度超过一倍。与此同时,用户每天提交的请求量也增长了 7 倍以上。
我们增加了许多独特的功能,例如 Personal Intelligence,让回复变得更加个性化,更实用。迄今为止,我们的 Nano Banana 图像生成模型已生成超过 500 亿张图像。它成为了过去一年的明星产品,展现了世界蕴藏的巨大创造力。
自然对话的 AI 体验
此外,还有大量潜在的生产力有待释放。在过去一年里,我们一直在努力让用户能够直接在产品中与 Gemini 进行更自然的对话。不久前,Google Maps 迎来了十年来的最大升级,推出了全新的 Ask Maps 功能,用户现在可以直接用更复杂、篇幅更长的自然语言向地图提问。
现在,我们正将这种能够自然对话的 AI 扩展到更多产品中:
Ask YouTube
每天都有无数用户来到 YouTube 寻找各类问题的答案。虽然平台上拥有海量的优质视频,但有时用户很难快速找到切入点。
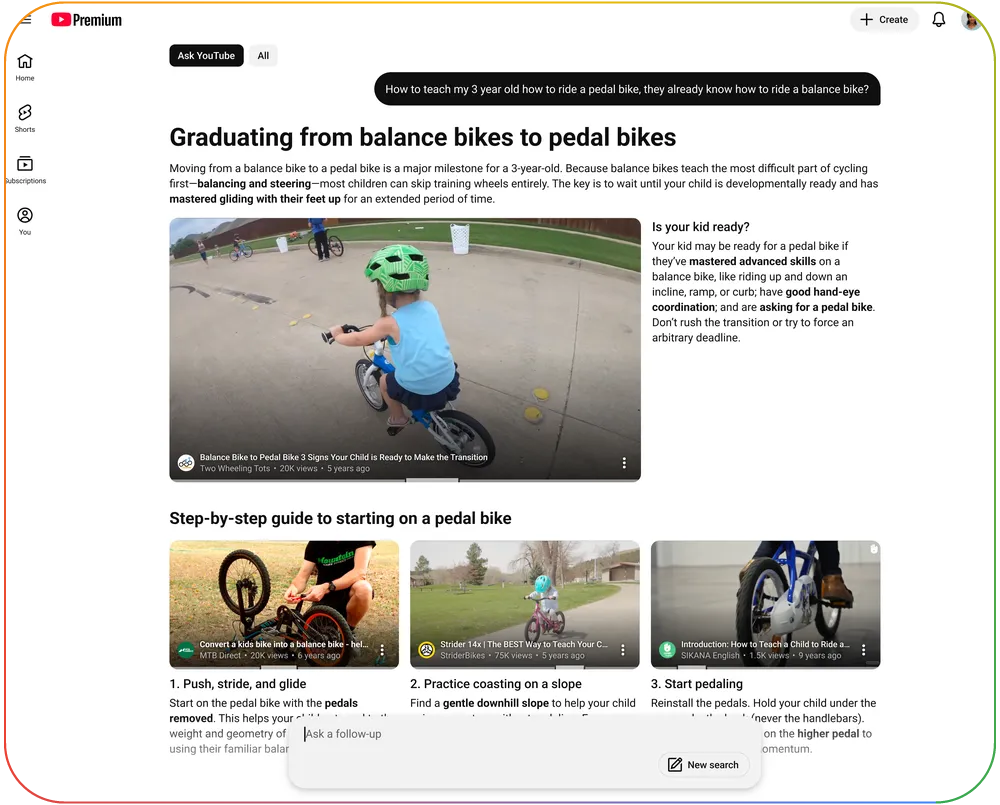
Ask YouTube 彻底重构了这一体验,让视频中的信息变得非常易于理解和浏览。AI 不仅能精准推荐最符合用户兴趣的视频,更重要的是,它能直接跳转到视频中最契合用户需求的核心片段。该功能目前已开始小范围测试,并计划于今年夏季在美国广泛推广。
语音驱动的 Docs Live
很多时候,我们都希望处理事务的速度能像说话一样快。得益于我们在音频模型上的技术飞跃,这在今天变得更为现实。
全新功能 Docs Live 将这一体验推向了新的高度。以往使用 Gemini 创建文档,用户需要输入非常精准的提示词。而现在通过 Docs Live,用户只需口头将脑海中的想法表达出来,Gemini 就能高效地帮用户完成后续的工作。
在未来,用户可以用声音来创建和编辑文档。Docs Live 将于今年夏季向订阅用户开放,届时,强大的语音功能也将同步引入 Gmail 和 Keep。
撑起海量技术创新的基础
看到创新在我们的产品中以如此迅猛的速度推进,实在令人惊叹。要在支持全球海量用户的同时,服务于全球开发者和企业客户,需要对基础设施进行大量投入。
我们一直在为现在和未来进行布局:2022 年我们的年资本支出 (capex) 为 310 亿美元,而到了今年,这个数字预计将翻大约 6 倍,约 1800 亿美元左右。其中,自主研发的定制芯片是我们投入的核心部分。
十年前,我们首次在 I/O 上发布了第一代 TPU。自那时起,我们改变了整个行业构建 AI 的方式。近期在 Cloud Next 大会上,我们正式宣布了第 8 代 TPU。这一次,我们首次采用了双芯片设计,针对训练和推理的不同需求设计的硬件架构:TPU 8t 和 TPU 8i。
TPU 8t 针对大规模预训练进行了优化,其原始算力几乎是上一代芯片的近 3 倍。在训练基础设施方面我们采用了截然不同的方法。借助 JAX 和 Pathways 框架,我们的模型训练不再受到单一大型数据中心的限制,而是可以无缝地将训练任务分布到全球多个站点,在全球范围内训练 100 万个 TPU。
这让我们拥有了构建全球最大训练集群的能力,对于模型构建者而言,这意味着可以在几周内而不是几个月内训练出更大、更强大的模型。
TPU 8i 专为模型推理而设计。我们显著提升了每个环节的速度。因为在深耕搜索的 27 年里我们学到了最核心的一点:运行速度十分重要。
除了追求速度,我们也关注可持续的能效表现。这两款全新芯片在能效上表现卓越,每瓦特性能 (performance-per-watt) 均实现了高达 2 倍的提升。
Gemini Omni 模型
得益于 TPUs 的进展,我们在模型、编程和智能体等领域持续推进算力性能的发展。借助世界模型 (World Models) ,AI 正在从文本预测迈向模拟现实物理世界。我们也一直在不断突破这类模型能力的边界。
Gemini Omni 是我们推出的全新模型,能够基于任意输入生成任意输出模态的内容。我们将率先推出视频输出能力,并在未来逐步扩展至图片和文本。
该模型将 Gemini 的核心智能与我们的生成式媒体模型深度融合,在现实世界的理解能力上实现了巨大飞跃。我们今天正式推出 Omni 系列的首个模型——Gemini Omni Flash。
Gemini Omni Flash 即日起正式上线,用户可以在 Gemini app、Google Flow 和 YouTube Shorts 中使用。未来几周内,该模型也将通过 API 向开发者和企业客户全面开放。
SynthID 技术升级与合作伙伴
随着生成式 AI 的技术演进,对内容透明度的需求也变得愈发重要。研究表明,用户单凭肉眼,能正确识别高质量深度伪造 (Deepfake) 视频的概率仅为四分之一左右。
三年前,我们推出了 SynthID——一种肉眼无法察觉的水印技术。自上线以来,SynthID 已经累计为超过 1000 亿张图片和视频、以及相当于 6 万年时长的音频内容添加数字水印。
现在,数百万用户在利用 Gemini app 中的 SynthID 检测工具验证 AI 生成内容。如今,我们更进一步,在核心产品中加入内容凭证验证 (Content Credentials verification) 功能。
该功能将帮助用户识别内容来源于相机拍摄还是 AI 生成,以及是否经过生成式 AI 工具编辑。为了让更多用户能够便捷使用这些工具,我们计划把 Content Credentials 和 SynthID 核验功能直接嵌入 Google 搜索和 Chrome 浏览器中。
当然,只有当更多合作伙伴选择为其 AI 生成的内容添加水印,这项技术才能真正起效。继去年 NVIDIA 加入之后,今天我们非常高兴地宣布,OpenAI、Kakao 以及 Eleven Labs 也将采用 SynthID 水印标准。我们很开心看到这种跨行业的紧密协作,期待未来能与更多合作伙伴携手,共同树立 AI 时代的数字安全与透明度标准。
Gemini 3.5 Flash
几个月前我们发布了 Gemini 3 模型的完整系列,这也是我们目前最受欢迎的模型系列。我们很高兴看到广大开发者把 Flash 当成日常开发的主力工具,并基于 Pro 模型强大的深度推理和多模态能力构建了许多精彩的应用体验。与此同时,我们也持续专注于提升模型在智能化编程、长周期任务以及现实工作流中的实际表现。
今天,我们正式推出 Gemini 3.5 Flash,这是我们首次推出的融合了前沿智能与行动力的模型。它有两大核心技术突破:
与 Gemini 3.1 Pro 相比,3.5 Flash 在几乎所有基准测试中都表现更优。它在编程方面取得了巨大的进步,尤其在 GDPVal 评分上实现了跨越式的飞跃。该指标涵盖了许多现实世界中具有实际经济价值的任务。
Gemini 3.5 Flash 是一款非常强大的模型,它处于技术前沿,堪比当前最优模型,同时保持了极高的运行速度。这也是为什么对比智能水平与输出速度来看,它在右上方象限中是独一档的存在。从每秒 Token 的输出量来看,其速度达到了其他同类模型的 4 倍。
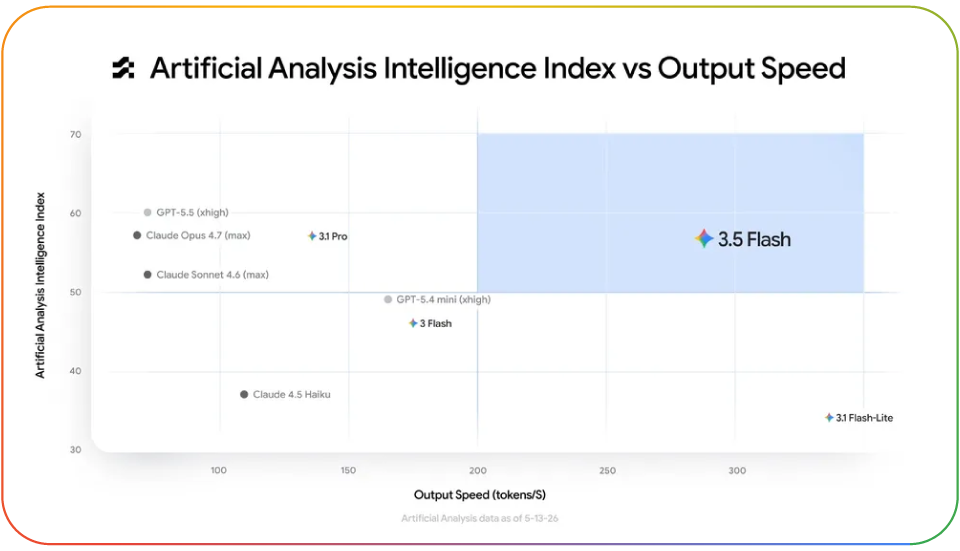
这款新模型在 Google 内部的研发工作中带来了颠覆性的变化。我们一直将 3.5 Flash 与全新重构的智能体化开发平台 Antigravity结合使用,这使得我们内部开发构建的速度得到了显著提升。
今年 3 月,我们内部的 AI 编程工具每天处理的 token 量达到 5000 亿个,并且每隔几周就会翻倍。而如今,我们每天处理超过 3 万亿个 token。这种超大规模的运行形成了强大的数据反馈闭环,协助我们持续优化并提升 3.5 模型的实际表现。
Flash 模型令人惊艳之处在于,它不仅能提供前沿级别能力,价格却不到同类前沿模型的一半。我们听到很多企业反馈,截止 5 月,其全年模型 token 预算就已接近耗尽。
企业若将 Flash 模型与其他前沿模型组合使用,将能够节省巨额的开支。目前头部的科技企业每天大约需要处理 1 万亿个 token。如果他们选择将其中 80% 的日常工作负载从其他前沿模型迁移到 Gemini 3.5 Flash 上,每年将节省超过 10 亿美元。这是一笔可观的成本节约,企业可以重新投入到企业核心业务。
即日起,Gemini 3.5 Flash 将在我们的各类产品和 API 中全面开放。同时,我们也在全力研发 Gemini 3.5 Pro。该模型目前已在 Google 内部投入使用,展现出了极大的性能提升,我们非常期待在下个月将其正式推出。
Antigravity 2.0
我们也同步将 3.5 Flash 引入 Antigravity 平台,面向开发者开放。
Antigravity 正在突破编程环境的局限,演变为一个可以开发和管理 AI 智能体集群 (cohorts of autonomous AI agents) 的综合平台。
其中包括 Antigravity 2.0,一款能够作为智能体交互核心枢纽的全新独立桌面应用,让任何用户都可以协调编排多个智能体去协同完成各种任务。同时,我们还在该平台内置了进一步优化的 Flash 版本,其响应速度达到了其他前沿模型的 12 倍。
用户即日起可在 Antigravity 中率先体验。
个人 AI 智能体 Gemini Spark
Gemini 3.5 与 Antigravity 正在开启一个由智能体和智能体能力驱动的全新世界。此前,我们已经面向开发者和企业用户推出了智能体。现在,我们致力于在确保安全可靠的前提下,将智能体的能力带给广大普通用户,让每个人都能从中受益。
今天起,用户将得以在 Google 的多款产品中体验。
我个人非常期待的 Gemini Spark——这是内置在 Gemini app 中的个人 AI 智能体,能够协助用户处理数字事务,并在用户的指导和授意下代执行任务。
运行在 Google Cloud 的专属虚拟机上,能够提供 24 小时全天候服务,用户无需在本地设备上维持程序运行。
由 Gemini 3.5 模型与 Google Antigravity harness 驱动,能够在后台轻松执行长周期、多步骤的复杂任务。
Spark 将与各类工具实现无缝集成,将率先与 Google 生态工具进行整合,并在未来几周内,通过 MCP 接入第三方工具。
用户可以通过最便利的方式与 Spark 协作,直接在 Gemini app 中使用,或者在不久后,通过电子邮件和聊天软件与其交互。
在 Android 设备上,用户可以通过今年晚些时候推出的全新 UI 交互空间 Android Halo,查看 Spark 等智能体的实时更新和任务进度。今年夏季,Spark 还将直接内置于 Chrome 浏览器中,作为用户的智能浏览器助手协助用户在全网处理各项事务。
我们本周开始向可信测试人员正式推出 Gemini Spark,并计划于下周向美国的 Google AI Ultra 订阅用户开放 Beta 测试版。
智能体时代的搜索
Gemini Spark 是首款基于 3.5 模型和 Antigravity 构建的体验。这种能力的融合,帮助我们加速实现公司使命,并为创新产品使其更具使用价值提供了全新途径。
随着我们步入智能体时代,Google 搜索将变得比以往任何时候都更加实用和强大。今天,我们正式在搜索中引入信息智能体 (Information Agents) 。
这些个性化 AI 智能体可以在后台被设置为全天候运行。它们会在恰当的时机找到用户所需的关键信息,并协助用户采取行动。信息智能体功能将于今年夏天率先面向 Google AI Pro 和 Ultra 订阅用户推出。
我们构建真正智能化搜索的另一种方法是为其引入智能编程能力。借助 Gemini 3.5 Flash 和 Google Antigravity 的能力,Google 搜索将能够针对用户的具体问题打造定制化体验,例如动态布局和交互式视觉效果。这些生成式 UI 能力将于今年夏天向所有搜索用户免费开放。
对于那些需要反复跟进的长周期任务,Google 搜索可以更进一步:构建一个持久的自定义仪表板或进度追踪器 (Persistent dashboard) ,方便用户随时返回查看并推进进度。
用户可以将这些视为针对个人特定任务的迷你应用程序 (Mini apps) 。未来几个月里,用户将能够直接在搜索中利用 Antigravity 构建自定义体验,该功能将率先面向美国的 Google AI Pro 和 Ultra 订阅用户开放。
智能体 Gemini 时代的更多新品
以下是我们在今年 I/O 大会上分享的其他进展:
每日简报 (Daily Brief) 是即将内置于 Gemini app 的又一款开箱即用型智能体。它提供个性化摘要,自动分析并归纳用户的收件箱、日历和待办事项,提炼出当天最需要用户关注的核心要务。
它不仅仅是简单的数据摘要,还能进行优先级排序、整理信息并提出后续步骤建议。所有这些都浓缩在这份简洁明了、便于快速浏览的晨间简报中。
Google Flow 是今天面向所有用户推出的一款全新智能体,它可以根据用户的输入,在用户的控制下,对复杂的任务进行推理与规划。基于 Gemini 模型构建,这款产品对用户的项目背景具备深刻的理解,能协助用户进行早期的头脑风暴、内容撰写与编辑。
用户甚至可以直接在 Flow 中使用氛围编程 (Vibe code) 定制任何用户想要的创意工具,例如用于设计视频特效、手绘动画或图层文本混合的小工具。
Google Pics 是我们全新的 AI 图像创作与编辑工具,基于最新的 Nano Banana 模型构建,可帮助用户使用所需的创意功能。无论用户是从空白画布开始设计,还是编辑现有的照片,Pics 都会将画面中的每一个元素视为一个独立的、可交互的对象,而不是一张扁平的静态的图。
这让用户可以创建、替换或修改特定细节,让画面符合预期。Google Pics 即日起向可信任测试人员开放,并将在今年夏天晚些时候向 Workspace 中的 Google AI Pro 和 Ultra 订阅用户正式推出。
智能眼镜 (Intelligent Eyewear) 最新进展:我们还分享了在去年初次亮相的Google 智能眼镜项目的最新成果。其中包括可以为用户提供耳边实时语音协助的音频眼镜 (audio glasses),以及在用户需要时立即呈现现实所需信息的显示眼镜 (display glasses) 。
这两款设备都能让用户解放双手,只需向 Gemini 提问即可随时获取支持。音频眼镜将率先上市,计划于今年秋季晚些时候推出。
Gemini for Science 平台汇聚了一系列 AI 工具,旨在加速科学研究。它基于 Gemini 的深度推理和研究能力以及 Deep Think 和 Deep Research 的能力,新增了 Labs 上的全新实验和 Science Skills,可将 Google Antigravity 等智能体平台无缝连接到全球 30 多个主流的生命科学核心数据库和专业工具中。
用户即日起可在 Google Labs 申请体验 Gemini for Science ,而 Science Skills 今天已在 GitHub 以及 Antigravity 平台中上线。
纵观我们从 TPU 8i 的基础设施到 Gemini 3.5 与 Antigravity 的全栈式创新,可以确定的是:我们已经迈入了智能体化的 Gemini 时代。
我非常期待看到这些全新的技术能力如何进一步协助我们把公司使命落到实处,并让我们的产品变得更加平实、好用,切实助力全球每一个地方的每一个人。






