





让每一张 GPU 释放极致 Tokens 输出
2022年11月,随着ChatGPT的发布,全球人工智能产业正式进入大模型时代。
过去两年间,从中国到中东,从北美到东南亚,大规模智算中心建设如火如荼。数以百万计的GPU被部署到数据中心,数万亿元资金投入到AI基础设施建设之中。
然而,一个新的问题逐渐显现:
算力很多,但真正稳定、高效、可运营、可盈利的算力并不多。
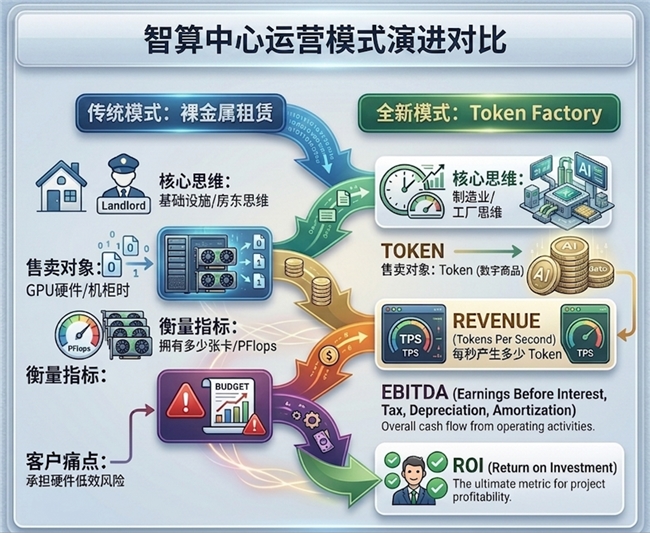
在传统模式下,智算中心主要采用“裸金属租赁”方式运营。客户按GPU卡时、服务器节点或机柜资源进行采购,运营商则通过出租硬件获取收益。
这种模式在云计算时代曾经有效,但在大模型时代却暴露出越来越多的局限性。
因为对于最终客户而言,他们真正需要的并不是GPU,而是模型训练结果和推理能力;对于智算中心而言,真正创造价值的也不是GPU本身,而是GPU最终产出的Token。
AI产业正在经历一次深刻转变:
从“卖GPU”,走向“卖Token”;从算力租赁,走向Token Factory运营。
算力产业正在进入 Token 经济时代
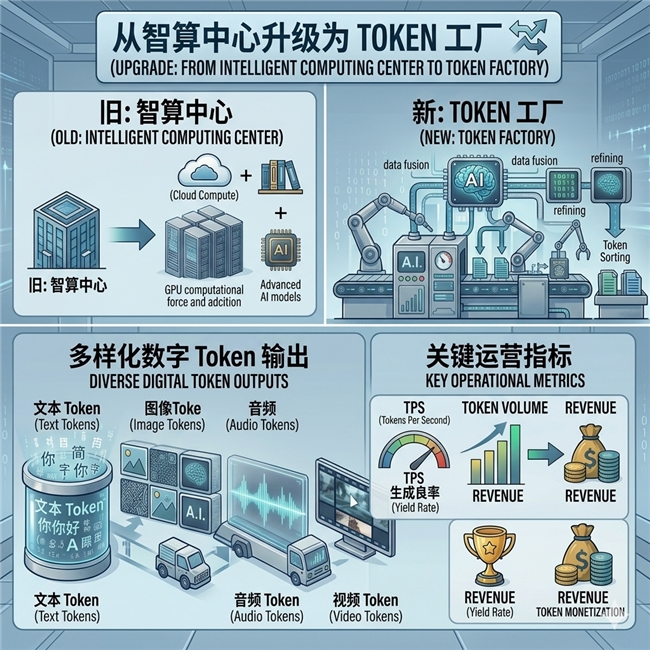
如果说GPU是工厂里的机器,那么Token就是工厂生产出来的产品。
今天的大模型推理服务,本质上是一种Token生产过程:
用户输入Prompt;
-
模型开始计算;
-
GPU完成推理;
-
最终输出Token;
因此,衡量一个智算中心经营水平的关键指标,已经不再是:
拥有多少张GPU;
-
部署了多少PFlops;
-
建设了多少机柜;
而是:
每秒产生多少Token(TPS);
-
每分钟产生多少Token(TPM);
-
每年能够销售多少Token;
-
每百万Token成本是多少;
-
每张GPU每天能够创造多少Token价值;
在这种背景下,全球领先AI企业开始逐步采用Token作为经营和计费单位。
从OpenAI、Anthropic到Google Gemini,再到DeepSeek、Qwen等大模型服务商,商业模式都正在从GPU资源租赁转向Token运营。
Token已经成为AI时代新的“数字商品”。
而智算中心,也正在演变为:
Token Factory时代的新挑战
当算力中心变成Token工厂后,新的问题出现了。
同样1000张GPU集群:
为什么有的集群每天可以生产3亿Token;
而有的集群只能生产1亿Token?
为什么同样采购H100或B200:
有的企业能够快速盈利;
有的企业却长期亏损?
问题的根源在于:
GPU数量并不等于Token产能。
影响Token产出的因素远远超过硬件本身。
例如:
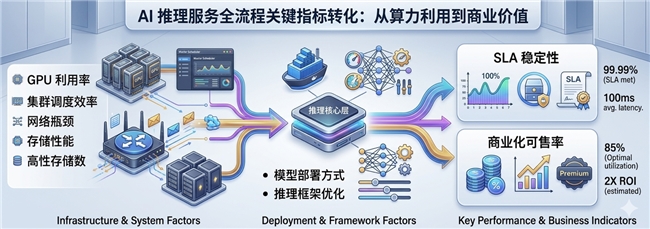
以上因素共同决定了:
一张GPU最终能创造多少Token价值。
因此,AI算力投资商需要一种新的经营方法论。
沨呵智慧提出 TEF:Token Efficiency Factor
为了量化Token生产效率,沨呵智慧率先提出:
TEF(Token Efficiency Factor)
即:
Token效率因子。
其定义为:
实际Token产出 ÷ 理论Token产出。
简单来说:
TEF衡量的是GPU资源被转化为Token产出的效率。
例如:
某集群理论可达到:
700,000 TPS
实际运行仅达到:
210,000 TPS
那么:
TEF = 30%
这意味着:
70%的潜在产能没有转化为真实业务价值。
在大量行业实践中,沨呵智慧发现:
许多智算中心的TEF仅为20%-35%。
【沨呵精益智算的核心能力,正是帮客户找回这消失的 70% 产能】
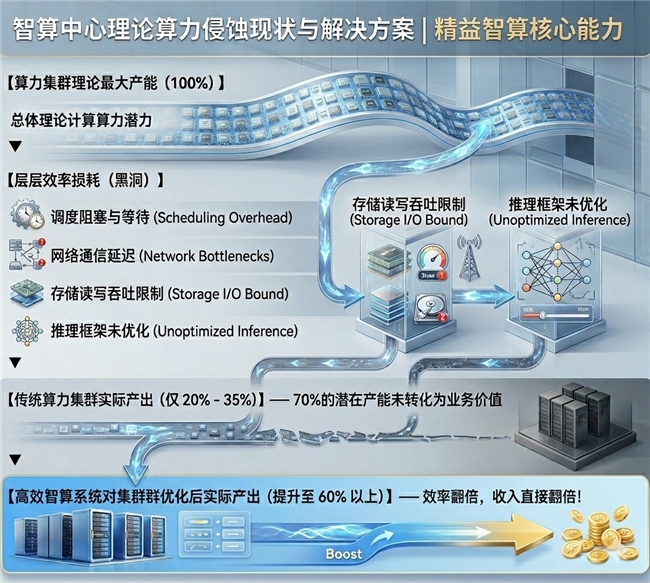
这意味着:
大量GPU资源处于闲置、等待、阻塞或低效运行状态。
而通过精益调度、智能运维和全链路优化,TEF往往能够提升至60%以上。
这不仅意味着性能提升,
更意味着收入提升。
*有文章写 GPU 效率提升至 90%以上,这通常是单卡或多卡 SXM单服务器测试结果;因为 NLP LLM 模型训推特性,在GPU集群环境受网络和存储带宽限制 下, GPU集群规模越大单卡平均 MFU 效率越低。欲知具体原因可查阅字节跳动 2024 年发布的论文《MegaScale: Scaling Large Language Model Training to More Than 10,000 GPUs》,关于 GPU MFU 效率随集群规模线性下降和如何保持集群稳定性有深入分析。
从TEF到TFI:Token工厂经营指标体系
在制造业中,人们通过OEE衡量工厂效率。
在Token Factory时代,沨呵智慧进一步提出:
TFI(Token Factory Index)
Token工厂指数。
计算方式为:
TFI = TEF × SLA × Sell Through
其中:
TEF:Token生产效率;
SLA:服务可用率;
Sell Through:商业化可售率;
TFI反映了:
一个Token工厂最终能够将多少理论产能转化为实际收入。
例如:

*以上经营效率提升倍数仅为概算,具体以 GPU 集群实际生产条件为准。
TFOM:Token Factory Operating Model
为了帮助客户从GPU硬件运营转向Token运营,
沨呵智慧进一步构建:
TFOM(Token Factory Operating Model)
Token工厂经营模型。
TFOM将智算中心视为一座数字化工厂。
模型核心链路为:
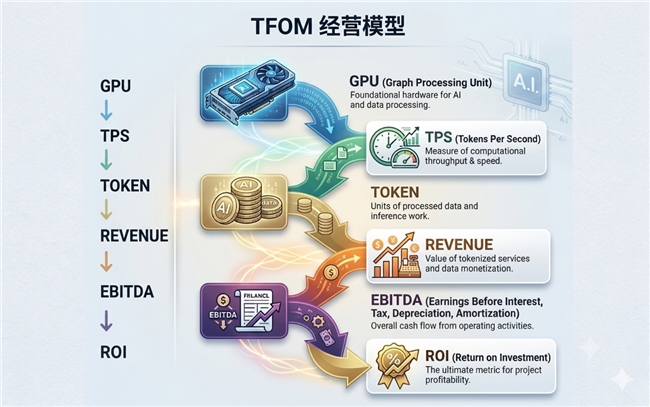
通过TFOM,
客户不仅能够看到:
“拥有多少GPU”,
更能够看到:
“这些GPU究竟创造了多少收入和利润”。
TFOM首次实现:
技术指标与财务指标的统一。
让:
TTFT、TPS、TPM
与:
Revenue、EBITDA、ROI
建立直接关联。
*这是算力中心财务投资人最关心的问题,一套优秀的 TFOM 运营模型可以给投资人带来绝对的信心,同时也代表投资人愿意投入更多的资本。
让1000张GPU发挥2167张GPU的价值
在实际项目中,
沨呵经常采用“Equivalent GPU”概念。
即:优化后的等效GPU数量。
例如:
1000张B200集群,
TEF从30%提升到65%。
那么:
Equivalent GPU
≈ 2167张GPU
换句话说:
客户无需再采购额外1167张GPU,
即可获得相同Token产能。
这意味着:
数亿元级别的资本支出节约。
沨呵将其定义为:
Avoided GPU CapEx
即:
避免新增GPU投资。
对于大型智算中心投资商而言,
在 Tokens 运营时代,这不仅代表同样资金比同行更高的 ROI 收益,在高端 GPU服务器 一机难求的当下,投资人可以在全球 Tokens 市场具备更大的投资决策空间,可以更灵活自如把控投资时机和投资规模。
从算力中心走向Token工厂
AI产业的发展正在进入新的阶段。
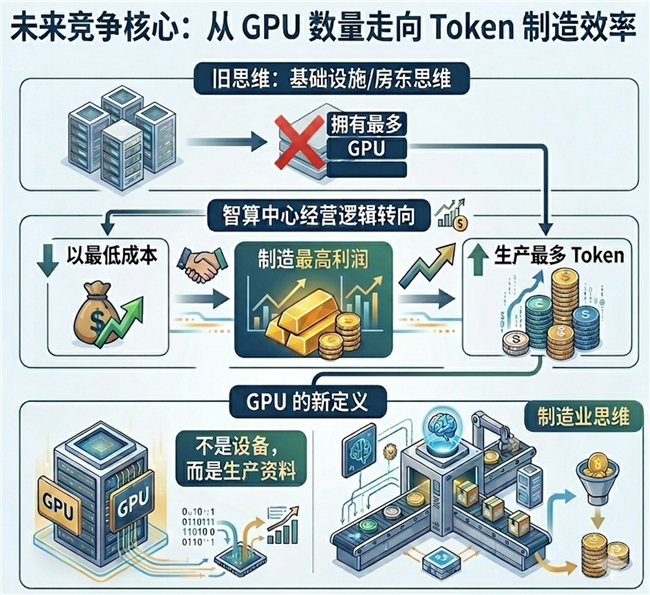
未来竞争的核心,
不再是谁拥有最多GPU。
而是谁能够:
以最低成本,
生产最多Token,
创造最高利润。
这意味着:
智算中心的经营逻辑正在从基础设施思维,
转向制造业思维。
GPU不再只是设备。
而是生产资料。
Token不再只是模型输出。
而是数字商品。
而沨呵智慧正在通过:
TEF(Token Efficiency Factor)← 沨呵精益智算优化能力
-
TFI(Token Factory Index)← 智算中心运营能力
-
TFOM(Token Factory Operating Model)← Token经济经营能力
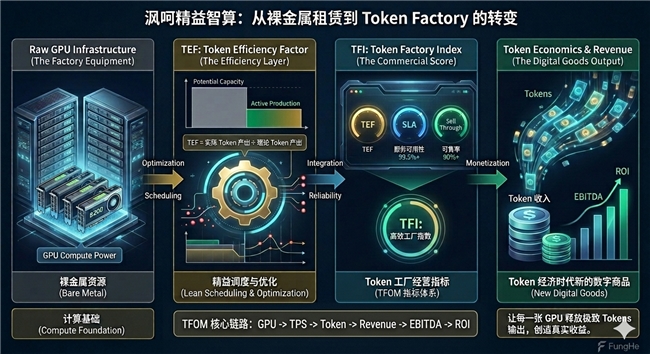
构建Token Factory时代的新一代经营方法论。
让每一张GPU释放极致 Tokens 输出。
让每一个Token创造真实收益。
推动全球智算产业从“算力批发时代”,迈向“Token精细化运营时代”。
声明:本站转载此文目的在于传递更多信息,并不代表赞同其观点和对其真实性负责。如涉及作品内容、版权和其它问题,请在30日内与本网联系,我们将在第一时间删除内容,本网站对此声明具有最终解释权。













