
DoNews6月23日消息,字节跳动今日在火山引擎官网上线了豆包 Seed 2.1 系列模型,包括 Pro 和 Turbo 版本,Seed-Evolving 模型也进行了迭代。
Seed2.1 以解决日常生活、专业工作和前沿探索中的复杂需求为研发目标,持续引入内外部用户和开发者的反馈,并结合真实案例校准模型优化方向;评估上,我们也更关注模型在实际工作流中的表现,而非仅依赖静态基准分数。
更可靠的通用 Agent 能力:Seed2.1 通用 Agent 能力显著提升,并进一步强化跨工具、跨环境的任务交付能力。在面对高经济价值的办公任务和个人生活的复杂咨询时,可稳定完成项目规划、文件处理、工具调用等多步骤任务,产出可落地的结果。
更稳定的代码工程交付能力:Seed2.1 提升了 Coding 的端到端交付能力,可在真实企业级开发任务中完成需求理解、功能实现、bug 修复、运行环境搭建和结果验证等任务,形成稳定交付。
更强劲的多模态等基础能力:Seed2.1 在多模态理解、知识、推理等基础能力上进一步提升,对复杂视觉信息和视频内容处理更准确,为 Agentic 场景、代码工程和前沿探索提供基础支撑。
Seed2.1 系列模型已在豆包产品和 TRAE 上线,同时,该系列模型 API 已同步上线火山引擎。
Seed2.1 进一步强化了通用 Agent 能力,无论是面向高经济价值的工作任务还是面向个人生活的复杂咨询,模型都能可靠交付。面向高经济价值的工作任务,过去,用户可能需要咨询外部顾问、专业服务团队来辅助完成;现在,模型可以参与资料分析、方案设计、内容规划和结果整理,帮助用户推进原本需要专业支持的工作,实现降本增效。
Seed2.1 在 Workspace Bench、Agent Startup Bench 基准上表现稳定,Seed2.1 Pro 在 GDPval 基准上获得最高分。其中,Workspace Bench 关注工作中对于复杂文件的信息检索、关联理解和结果生成;Agent Startup Bench 通过调研、访谈真实的 AI 原生创业公司,结合专家意见综合评估模型的回答质量;GDPval 则衡量模型在真实世界工作任务中的完成质量和经济价值。
评测结果说明,Seed2.1 在贴近真实工作任务的 AI 工作流中,能够在复杂材料和任务目标之间建立联系,并产生具有经济收益的交付。此外,在更高难度、更专业的任务上,Seed2.1 也有较好表现。
其中,Seed2.1 Pro 在 Agents' Last Exam(ALE)基准评测中,处于当前参评模型的第一梯队水平,体现出在复杂专业任务上的较强竞争力。
值得注意的是,该评测发布不久,各模型短期内难以针对该测试进行充分定向优化,能够更真实地衡量模型面对新任务场景时的泛化能力。
该结果表明,Seed2.1 所具备的任务规划、工具使用、长程执行、信息整合与结果交付等通用 Agent 能力,能够较好地迁移到此前未见的高门槛专业工作流中。
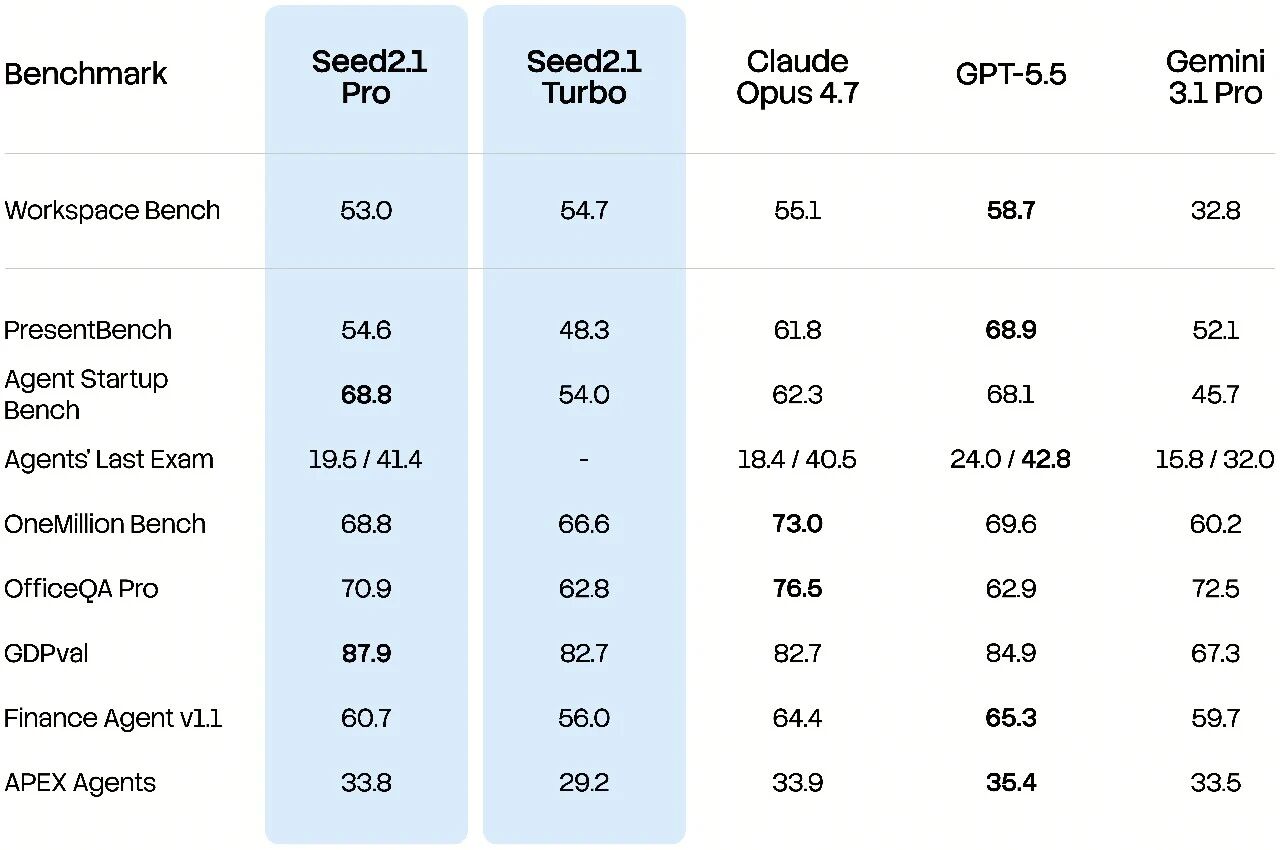
Agents' Last Exam 基准评测中,左侧为完整通过率,右侧为平均综合得分
面向个人生活中的复杂咨询场景,Seed2.1 系列模型回复的质量和可靠性进一步提升。这类需求往往不是简单问答,用户会同时提供咨询背景、过往记录、行业报告等多种信息,内容也分布在文档、PDF、图片等不同格式中,形成一个需要综合推理、判断、建议的复杂咨询场景。
Seed2.1 在 xDailyBench、Doubao Multi-Turn Bench 等基准上表现稳定,在 Toolathlon、SeedClawBench 等基准上保持竞争力。这说明模型在日常生活、学习研究等 30 多个垂类场景中,都能更好地理解真实用户需求,并结合用户偏好给出高质量的建议,必要时还能调用不同工具、使用合适的 Skill,产出可靠回复。
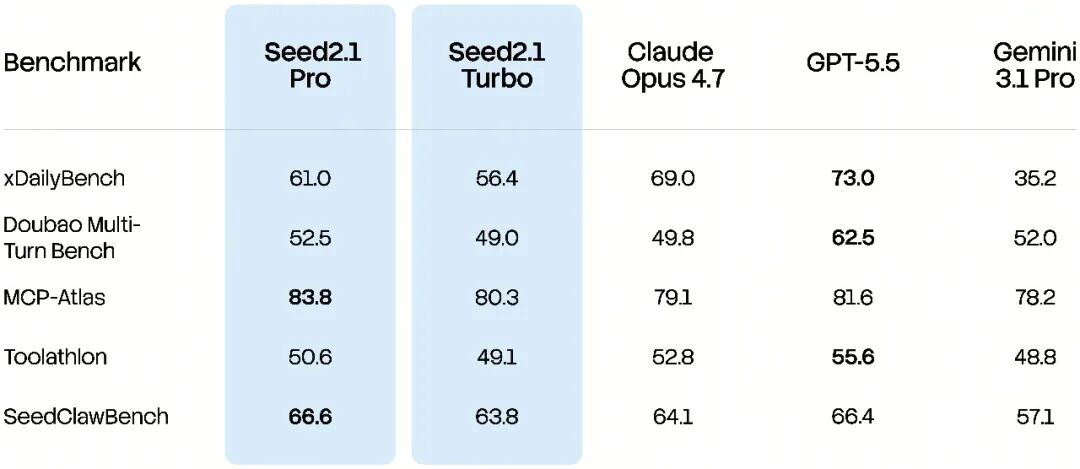
SeedClawBench 是由 Seed 自主开发的内部基准,用于评估在 OpenClaw 风格、面向用户的场景中,Agent 提供实际辅助的能力
此外,基于稳定的视觉理解能力,Seed2.1 能够在复杂任务中更好地处理视觉信息、理解用户目标,并推进后续执行与交付。Seed2.1 在 Claw-Eval (MM) 等 Visual Agent 相关基准上整体表现出较强的竞争力。
这意味着模型不仅能够理解文档、视频、图片、空间结构等复杂的视觉信息,还能围绕任务目标对视觉信息进行整理和分析,并形成可交互、可交付的 Agent 结果,例如基于多视角图像生成平面户型图,或根据视觉信息完成信息检索、内容生成和代码编写等任务。
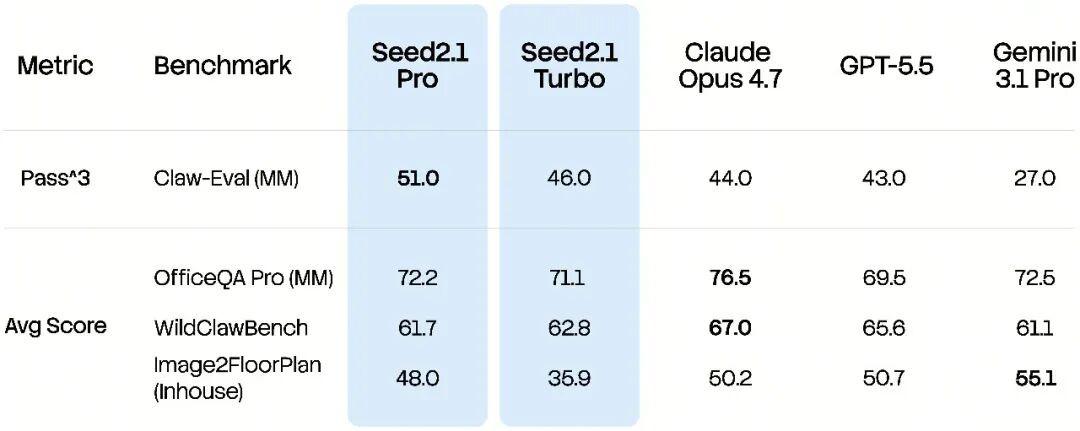
Image2FloorPlan 为内部自建评测集,考察的任务为理解多张真实照片并绘制平面户型图
在面向专业生产力场景的探索中,我们发现,真实工作流并非发生在某一个固定界面里,而是需要在聊天、搜索、浏览器、代码仓库、文件和外部工具之间切换。
因此 Seed2.1 进一步面向通用型 Computer-Use Agent (CUA) 方向优化,让模型能更稳定地在跨环境、跨工具和跨交互方式的任务中持续推进。
其中,面对手机 GUI 任务,模型需要理解屏幕内容、判断下一步操作,并完成点击、输入、切换应用等连续动作,Seed2.1 在 MobileWorld 基准中取得最高分,说明其在手机端任务中能够更稳定地推进操作。
同时,模型在 OSWorld 上保持竞争力,并通过强化学习,引导 Agent 自然地在 GUI 和非 GUI 动作空间之中切换最优选择,将完成任务所需的平均步数减少 16%,进一步提升任务执行效率。
此外,Seed2.1 在 CreativeWork 基准上同样表现突出。该基准覆盖了 Notion、Canva 和 Figma 三类具有代表性的环境,意味着模型在文档管理、视觉设计和界面编辑等多种任务中,都能理解复杂目标、分解执行步骤,并在工具调用与 GUI 交互之间自主切换,稳定地完成任务。
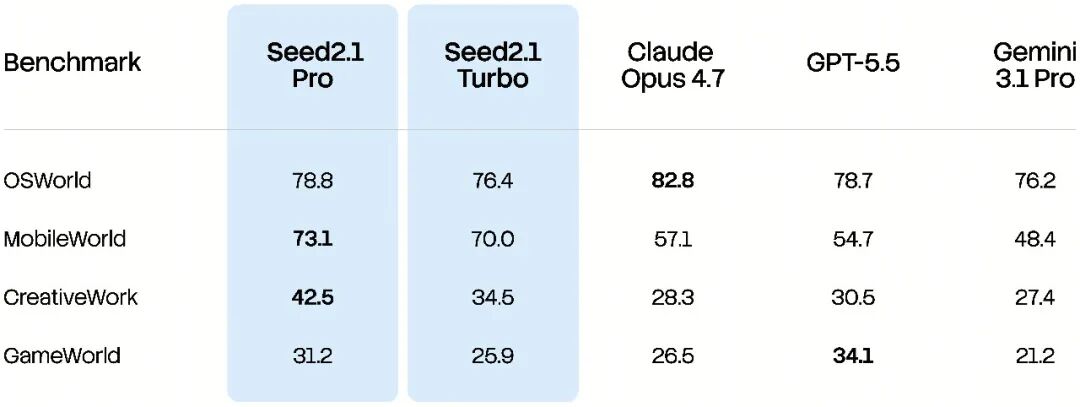
CreativeWork 是 Seed 自研的基准,用于评估 Agent 在真实生产力场景中协同使用 GUI 与 MCP 工具的能力






